8. Linear Equations and Matrix Algebra#
8.1. Overview#
Many problems in economics and finance require solving linear equations.
In this lecture we discuss linear equations and their applications.
To illustrate the importance of linear equations, we begin with a two good model of supply and demand.
The two good case is so simple that solutions can be calculated by hand.
But often we need to consider markets containing many goods.
In the multiple goods case we face large systems of linear equations, with many equations and unknowns.
To handle such systems we need two things:
matrix algebra (and the knowledge of how to use it) plus
computer code to apply matrix algebra to the problems of interest.
This lecture covers these steps.
We will use the following packages:
import numpy as np
import matplotlib.pyplot as plt
8.2. A two good example#
In this section we discuss a simple two good example and solve it by
pencil and paper
matrix algebra
The second method is more general, as we will see.
8.2.1. Pencil and paper methods#
Suppose that we have two related goods, such as
propane and ethanol, and
rice and wheat, etc.
To keep things simple, we label them as good 0 and good 1.
The demand for each good depends on the price of both goods:
(We are assuming demand decreases when the price of either good goes up, but other cases are also possible.)
Let’s suppose that supply is given by
Equilibrium holds when supply equals demand (\(q_0^s = q_0^d\) and \(q_1^s = q_1^d\)).
This yields the linear system
We can solve this with pencil and paper to get
Inserting these results into either (8.1) or (8.2) yields the equilibrium quantities
8.2.2. Looking forward#
Pencil and paper methods are easy in the two good case.
But what if there are many goods?
For such problems we need matrix algebra.
Before solving problems with matrix algebra, let’s first recall the basics of vectors and matrices, in both theory and computation.
8.3. Vectors#
A vector of length \(n\) is just a sequence (or array, or tuple) of \(n\) numbers, which we write as \(x = (x_1, \ldots, x_n)\) or \(x = \begin{bmatrix}x_1, \ldots, x_n\end{bmatrix}\).
We can write these sequences either horizontally or vertically.
But when we use matrix operations, our default assumption is that vectors are column vectors.
The set of all \(n\)-vectors is denoted by \(\mathbb R^n\).
Example 8.1
\(\mathbb R^2\) is the plane — the set of pairs \((x_1, x_2)\).
\(\mathbb R^3\) is 3 dimensional space — the set of vectors \((x_1, x_2, x_3)\).
Often vectors are represented visually as arrows from the origin to the point.
Here’s a visualization.
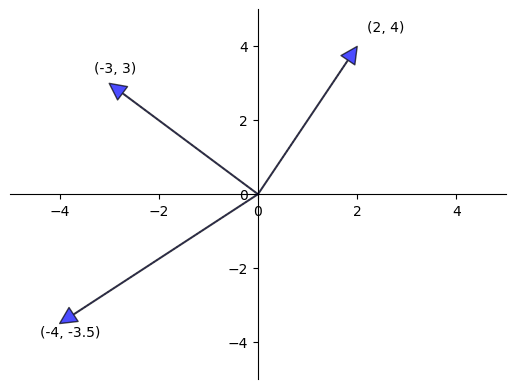
8.3.1. Vector operations#
Sometimes we want to modify vectors.
The two most common operators on vectors are addition and scalar multiplication, which we now describe.
When we add two vectors, we add them element-by-element.
Example 8.2
In general,
We can visualise vector addition in \(\mathbb{R}^2\) as follows.
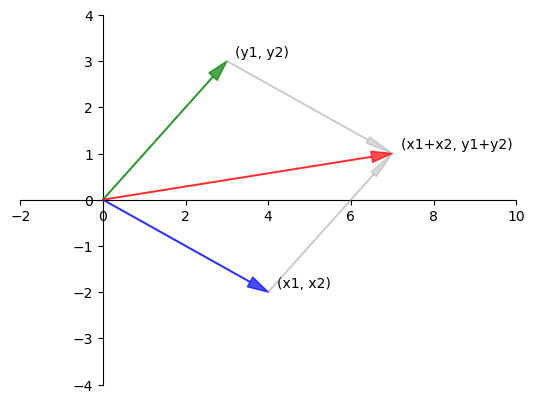
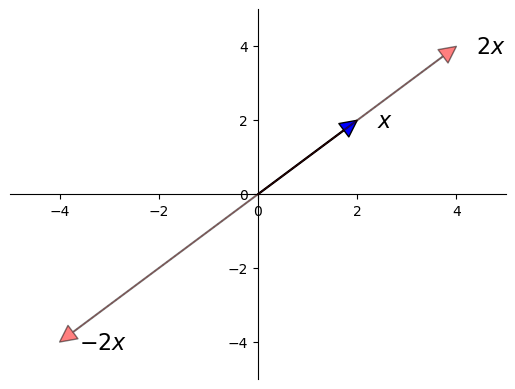
Scalar multiplication is an operation that multiplies a vector \(x\) with a scalar elementwise.
Example 8.3
More generally, it takes a number \(\gamma\) and a vector \(x\) and produces
Scalar multiplication is illustrated in the next figure.
In Python, a vector can be represented as a list or tuple,
such as x = [2, 4, 6] or x = (2, 4, 6).
However, it is more common to represent vectors with NumPy arrays.
One advantage of NumPy arrays is that scalar multiplication and addition have very natural syntax.
x = np.ones(3) # Vector of three ones
y = np.array((2, 4, 6)) # Converts tuple (2, 4, 6) into a NumPy array
x + y # Add (element-by-element)
array([3., 5., 7.])
4 * x # Scalar multiply
array([4., 4., 4.])
8.3.2. Inner product and norm#
The inner product of vectors \(x,y \in \mathbb R^n\) is defined as
The norm of a vector \(x\) represents its “length” (i.e., its distance from the zero vector) and is defined as
The expression \(\| x - y\|\) can be thought of as the “distance” between \(x\) and \(y\).
The inner product and norm can be computed as follows
np.sum(x*y) # Inner product of x and y
np.float64(12.0)
x @ y # Another way to compute the inner product
np.float64(12.0)
np.sqrt(np.sum(x**2)) # Norm of x, method one
np.float64(1.7320508075688772)
np.linalg.norm(x) # Norm of x, method two
np.float64(1.7320508075688772)
8.4. Matrix operations#
When we discussed linear price systems, we mentioned using matrix algebra.
Matrix algebra is similar to algebra for numbers.
Let’s review some details.
8.4.1. Addition and scalar multiplication#
Just as was the case for vectors, we can add, subtract and scalar multiply matrices.
Scalar multiplication and addition are generalizations of the vector case:
Example 8.4
In general for a number \(\gamma\) and any matrix \(A\),
Example 8.5
Consider this example of matrix addition,
In general,
In the latter case, the matrices must have the same shape in order for the definition to make sense.
8.4.2. Matrix multiplication#
We also have a convention for multiplying two matrices.
The rule for matrix multiplication generalizes the idea of inner products discussed above.
If \(A\) and \(B\) are two matrices, then their product \(A B\) is formed by taking as its \(i,j\)-th element the inner product of the \(i\)-th row of \(A\) and the \(j\)-th column of \(B\).
If \(A\) is \(n \times k\) and \(B\) is \(j \times m\), then to multiply \(A\) and \(B\) we require \(k = j\), and the resulting matrix \(A B\) is \(n \times m\).
Example 8.6
Here’s an example of a \(2 \times 2\) matrix multiplied by a \(2 \times 1\) vector.
As an important special case, consider multiplying \(n \times k\) matrix \(A\) and \(k \times 1\) column vector \(x\).
According to the preceding rule, this gives us an \(n \times 1\) column vector.
Here is a simple illustration of multiplication of two matrices.
There are many tutorials to help you further visualize this operation, such as
this one, or
the discussion on the Wikipedia page.
Note
Unlike number products, \(A B\) and \(B A\) are not generally the same thing.
One important special case is the identity matrix, which has ones on the principal diagonal and zero elsewhere:
It is a useful exercise to check the following:
if \(A\) is \(n \times k\) and \(I\) is the \(k \times k\) identity matrix, then \(AI = A\), and
if \(I\) is the \(n \times n\) identity matrix, then \(IA = A\).
8.4.3. Matrices in NumPy#
NumPy arrays are also used as matrices, and have fast, efficient functions and methods for all the standard matrix operations.
You can create them manually from tuples of tuples (or lists of lists) as follows
A = ((1, 2),
(3, 4))
type(A)
tuple
A = np.array(A)
type(A)
numpy.ndarray
A.shape
(2, 2)
The shape attribute is a tuple giving the number of rows and columns —
see here
for more discussion.
To get the transpose of A, use A.transpose() or, more simply, A.T.
There are many convenient functions for creating common matrices (matrices of zeros, ones, etc.) — see here.
Since operations are performed elementwise by default, scalar multiplication and addition have very natural syntax.
A = np.identity(3) # 3 x 3 identity matrix
B = np.ones((3, 3)) # 3 x 3 matrix of ones
2 * A
array([[2., 0., 0.],
[0., 2., 0.],
[0., 0., 2.]])
A + B
array([[2., 1., 1.],
[1., 2., 1.],
[1., 1., 2.]])
To multiply matrices we use the @ symbol.
Note
In particular, A @ B is matrix multiplication, whereas A * B is element-by-element multiplication.
8.4.4. Two good model in matrix form#
We can now revisit the two good model and solve (8.3) numerically via matrix algebra.
This involves some extra steps but the method is widely applicable — as we will see when we include more goods.
First we rewrite (8.1) as
Recall that \(p \in \mathbb{R}^{2}\) is the price of two goods.
(Please check that \(q^d = D p + h\) represents the same equations as (8.1).)
We rewrite (8.2) as
Now equality of supply and demand can be expressed as \(q^s = q^d\), or
We can rearrange the terms to get
If all of the terms were numbers, we could solve for prices as \(p = h / (C-D)\).
Matrix algebra allows us to do something similar: we can solve for equilibrium prices using the inverse of \(C - D\):
Before we implement the solution let us consider a more general setting.
8.4.5. More goods#
It is natural to think about demand systems with more goods.
For example, even within energy commodities there are many different goods, including crude oil, gasoline, coal, natural gas, ethanol, and uranium.
The prices of these goods are related, so it makes sense to study them together.
Pencil and paper methods become very time consuming with large systems.
But fortunately the matrix methods described above are essentially unchanged.
In general, we can write the demand equation as \(q^d = Dp + h\), where
\(q^d\) is an \(n \times 1\) vector of demand quantities for \(n\) different goods.
\(D\) is an \(n \times n\) “coefficient” matrix.
\(h\) is an \(n \times 1\) vector of constant values.
Similarly, we can write the supply equation as \(q^s = Cp + e\), where
\(q^s\) is an \(n \times 1\) vector of supply quantities for the same goods.
\(C\) is an \(n \times n\) “coefficient” matrix.
\(e\) is an \(n \times 1\) vector of constant values.
To find an equilibrium, we solve \(Dp + h = Cp + e\), or
Then the price vector of the n different goods is
8.4.6. General linear systems#
A more general version of the problem described above looks as follows.
The objective here is to solve for the “unknowns” \(x_1, \ldots, x_n\).
We take as given the coefficients \(a_{11}, \ldots, a_{nn}\) and constants \(b_1, \ldots, b_n\).
Notice that we are treating a setting where the number of unknowns equals the number of equations.
This is the case where we are most likely to find a well-defined solution.
(The other cases are referred to as overdetermined and underdetermined systems of equations — we defer discussion of these cases until later lectures.)
In matrix form, the system (8.9) becomes
Example 8.7
For example, (8.8) has this form with
When considering problems such as (8.10), we need to ask at least some of the following questions
Does a solution actually exist?
If a solution exists, how should we compute it?
8.5. Solving systems of equations#
Recall again the system of equations (8.9), which we write here again as
The problem we face is to find a vector \(x \in \mathbb R^n\) that solves (8.11), taking \(b\) and \(A\) as given.
We may not always find a unique vector \(x\) that solves (8.11).
We illustrate two such cases below.
8.5.1. No solution#
Consider the system of equations given by,
It can be verified manually that this system has no possible solution.
To illustrate why this situation arises let’s plot the two lines.
fig, ax = plt.subplots()
x = np.linspace(-10, 10)
plt.plot(x, (3-x)/3, label=f'$x + 3y = 3$')
plt.plot(x, (-8-2*x)/6, label=f'$2x + 6y = -8$')
plt.legend()
plt.show()
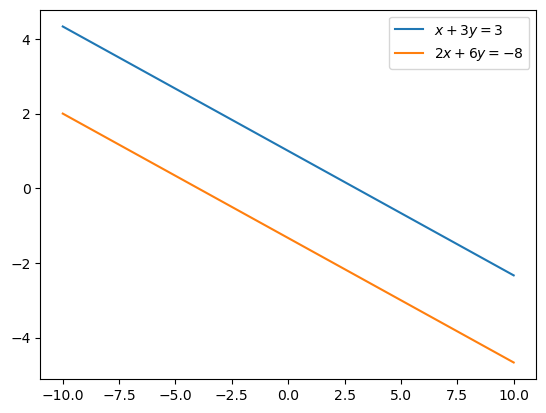
Clearly, these are parallel lines and hence we will never find a point \(x \in \mathbb{R}^2\) such that these lines intersect.
Thus, this system has no possible solution.
We can rewrite this system in matrix form as
It can be noted that the \(2^{nd}\) row of matrix \(A = (2, 6)\) is just a scalar multiple of the \(1^{st}\) row of matrix \(A = (1, 3)\).
The rows of matrix \(A\) in this case are called linearly dependent.
Note
Advanced readers can find a detailed explanation of linear dependence and independence here.
But these details are not needed in what follows.
8.5.2. Many solutions#
Now consider,
Any vector \(v = (x,y)\) such that \(x = 2y - 4\) will solve the above system.
Since we can find infinite such vectors this system has infinitely many solutions.
This is because the rows of the corresponding matrix
are linearly dependent — can you see why?
We now impose conditions on \(A\) in (8.11) that rule out these problems.
8.5.3. Nonsingular matrices#
To every square matrix we can assign a unique number called the determinant.
For \(2 \times 2\) matrices, the determinant is given by,
If the determinant of \(A\) is not zero, then we say that \(A\) is nonsingular.
A square matrix \(A\) is nonsingular if and only if the rows and columns of \(A\) are linearly independent.
A more detailed explanation of matrix inverse can be found here.
You can check yourself that the in (8.12) and (8.13) with linearly dependent rows are singular matrices.
This gives us a useful one-number summary of whether or not a square matrix can be inverted.
In particular, a square matrix \(A\) has a nonzero determinant, if and only if it possesses an inverse matrix \(A^{-1}\), with the property that \(A A^{-1} = A^{-1} A = I\).
As a consequence, if we pre-multiply both sides of \(Ax = b\) by \(A^{-1}\), we get
This is the solution to \(Ax = b\) — the solution we are looking for.
8.5.4. Linear equations with NumPy#
In the two good example we obtained the matrix equation,
where \(C\), \(D\) and \(h\) are given by (8.5) and (8.6).
This equation is analogous to (8.14) with \(A = C-D\), \(b = h\), and \(x = p\).
We can now solve for equilibrium prices with NumPy’s linalg submodule.
All of these routines are Python front ends to time-tested and highly optimized FORTRAN code.
C = ((10, 5), # Matrix C
(5, 10))
Now we change this to a NumPy array.
C = np.array(C)
D = ((-10, -5), # Matrix D
(-1, -10))
D = np.array(D)
h = np.array((100, 50)) # Vector h
h.shape = 2,1 # Transforming h to a column vector
from numpy.linalg import det, inv
A = C - D
# Check that A is nonsingular (non-zero determinant), and hence invertible
det(A)
np.float64(340.0000000000001)
A_inv = inv(A) # compute the inverse
A_inv
array([[ 0.05882353, -0.02941176],
[-0.01764706, 0.05882353]])
p = A_inv @ h # equilibrium prices
p
array([[4.41176471],
[1.17647059]])
q = C @ p # equilibrium quantities
q
array([[50. ],
[33.82352941]])
Notice that we get the same solutions as the pencil and paper case.
We can also solve for \(p\) using solve(A, h) as follows.
from numpy.linalg import solve
p = solve(A, h) # equilibrium prices
p
array([[4.41176471],
[1.17647059]])
q = C @ p # equilibrium quantities
q
array([[50. ],
[33.82352941]])
Observe how we can solve for \(x = A^{-1} y\) by either via inv(A) @ y, or using solve(A, y).
The latter method uses a different algorithm that is numerically more stable and hence should be the default option.
8.6. Exercises#
Exercise 8.1
Let’s consider a market with 3 commodities - good 0, good 1 and good 2.
The demand for each good depends on the price of the other two goods and is given by:
(Here demand decreases when own price increases but increases when prices of other goods increase.)
The supply of each good is given by:
Equilibrium holds when supply equals demand, i.e, \(q_0^d = q_0^s\), \(q_1^d = q_1^s\) and \(q_2^d = q_2^s\).
Set up the market as a system of linear equations.
Use matrix algebra to solve for equilibrium prices. Do this using both the
numpy.linalg.solveandinv(A)methods. Compare the solutions.
Solution to Exercise 8.1
The generated system would be:
In matrix form we will write this as:
import numpy as np
from numpy.linalg import det
A = np.array([[35, -5, -5], # matrix A
[-5, 25, -10],
[-5, -5, 15]])
b = np.array((100, 75, 55)) # column vector b
b.shape = (3, 1)
det(A) # check if A is nonsingular
np.float64(9999.99999999999)
# Using inverse
from numpy.linalg import det
A_inv = inv(A)
p = A_inv @ b
p
array([[4.9625],
[7.0625],
[7.675 ]])
# Using numpy.linalg.solve
from numpy.linalg import solve
p = solve(A, b)
p
array([[4.9625],
[7.0625],
[7.675 ]])
The solution is given by: $\( p_0 = 4.9625, \; p_1 = 7.0625 \;\; \text{and} \;\; p_2 = 7.675 \)$
Exercise 8.2
Earlier in the lecture we discussed cases where the system of equations given by \(Ax = b\) has no solution.
In this case \(Ax = b\) is called an inconsistent system of equations.
When faced with an inconsistent system we try to find the best “approximate” solution.
There are various methods to do this, one such method is the method of least squares.
Suppose we have an inconsistent system
where \(A\) is an \(m \times n\) matrix and \(b\) is an \(m \times 1\) column vector.
A least squares solution to (8.15) is an \(n \times 1\) column vector \(\hat{x}\) such that, for all other vectors \(x \in \mathbb{R}^n\), the distance from \(A\hat{x}\) to \(b\) is less than the distance from \(Ax\) to \(b\).
That is,
It can be shown that, for the system of equations \(Ax = b\), the least squares solution \(\hat{x}\) is
Now consider the general equation of a linear demand curve of a good given by:
where \(p\) is the price of the good and \(q\) is the quantity demanded.
Suppose we are trying to estimate the values of \(m\) and \(n\).
We do this by repeatedly observing the price and quantity (for example, each month) and then choosing \(m\) and \(n\) to fit the relationship between \(p\) and \(q\).
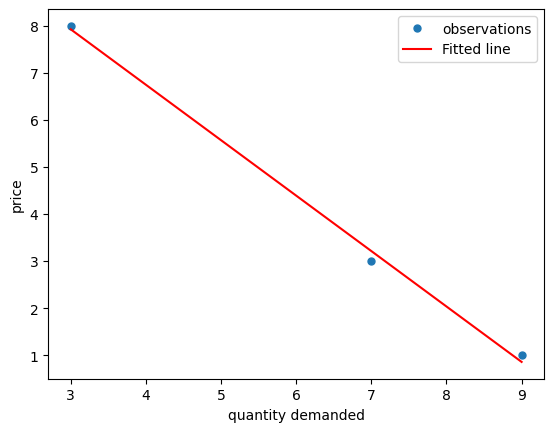
We have the following observations:
Price |
Quantity Demanded |
|---|---|
1 |
9 |
3 |
7 |
8 |
3 |
Requiring the demand curve \(p = m - nq\) to pass through all these points leads to the following three equations:
Thus we obtain a system of equations \(Ax = b\) where \(A = \begin{bmatrix} 1 & -9 \\ 1 & -7 \\ 1 & -3 \end{bmatrix}\), \(x = \begin{bmatrix} m \\ n \end{bmatrix}\) and \(b = \begin{bmatrix} 1 \\ 3 \\ 8 \end{bmatrix}\).
It can be verified that this system has no solutions.
(The problem is that we have three equations and only two unknowns.)
We will thus try to find the best approximate solution for \(x\).
Use the least-squares formula above and matrix algebra to find the least squares solution \(\hat{x}\).
Find the least squares solution using
numpy.linalg.lstsqand compare the results.
Solution to Exercise 8.2
import numpy as np
from numpy.linalg import inv
# Using matrix algebra
A = np.array([[1, -9], # matrix A
[1, -7],
[1, -3]])
A_T = np.transpose(A) # transpose of matrix A
b = np.array((1, 3, 8)) # column vector b
b.shape = (3, 1)
x = inv(A_T @ A) @ A_T @ b
x
array([[11.46428571],
[ 1.17857143]])
# Using numpy.linalg.lstsq
x, res, _, _ = np.linalg.lstsq(A, b, rcond=None)
x̂ = [[11.46428571]
[ 1.17857143]]
‖Ax̂ - b‖² = 0.07142857142857066
Here is a visualization of how the least squares method approximates the equation of a line connecting a set of points.
We can also describe this as “fitting” a line between a set of points.
fig, ax = plt.subplots()
p = np.array((1, 3, 8))
q = np.array((9, 7, 3))
a, b = x
ax.plot(q, p, 'o', label='observations', markersize=5)
ax.plot(q, a - b*q, 'r', label='Fitted line')
plt.xlabel('quantity demanded')
plt.ylabel('price')
plt.legend()
plt.show()
8.6.1. Further reading#
The documentation of the numpy.linalg submodule can be found here.
More advanced topics in linear algebra can be found here.