35. Markov Chains: Basic Concepts#
In addition to what’s in Anaconda, this lecture will need the following libraries:
!pip install quantecon
35.1. Overview#
Markov chains provide a way to model situations in which the past casts shadows on the future.
By this we mean that observing measurements about a present situation can help us forecast future situations.
This can be possible when there are statistical dependencies among measurements of something taken at different points of time.
For example,
inflation next year might co-vary with inflation this year
unemployment next month might co-vary with unemployment this month
Markov chains are a workhorse for economics and finance.
The theory of Markov chains is beautiful and provides many insights into probability and dynamics.
In this lecture, we will
review some of the key ideas from the theory of Markov chains and
show how Markov chains appear in some economic applications.
Let’s start with some standard imports:
import matplotlib.pyplot as plt
import quantecon as qe
import numpy as np
import networkx as nx
from matplotlib import cm
import matplotlib as mpl
from mpl_toolkits.mplot3d import Axes3D
from matplotlib.animation import FuncAnimation
from IPython.display import HTML
from matplotlib.patches import Polygon
from mpl_toolkits.mplot3d.art3d import Poly3DCollection
35.2. Definitions and examples#
In this section we provide some definitions and elementary examples.
35.2.1. Stochastic matrices#
Recall that a probability mass function over \(n\) possible outcomes is a nonnegative \(n\)-vector \(p\) that sums to one.
For example, \(p = (0.2, 0.2, 0.6)\) is a probability mass function over \(3\) outcomes.
A stochastic matrix (or Markov matrix) is an \(n \times n\) square matrix \(P\) such that each row of \(P\) is a probability mass function.
In other words,
each element of \(P\) is nonnegative, and
each row of \(P\) sums to one
If \(P\) is a stochastic matrix, then so is the \(k\)-th power \(P^k\) for all \(k \in \mathbb N\).
You are asked to check this in an exercise below.
35.2.2. Markov chains#
Now we can introduce Markov chains.
Before defining a Markov chain rigorously, we’ll give some examples.
35.2.2.1. Example 1: Economic states#
From US unemployment data, Hamilton [Hamilton, 2005] estimated the following dynamics.
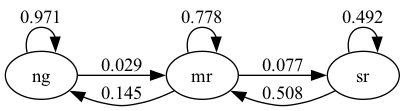
Here there are three states
“ng” represents normal growth
“mr” represents mild recession
“sr” represents severe recession
The arrows represent transition probabilities over one month.
For example, the arrow from mild recession to normal growth has 0.145 next to it.
This tells us that, according to past data, there is a 14.5% probability of transitioning from mild recession to normal growth in one month.
The arrow from normal growth back to normal growth tells us that there is a 97% probability of transitioning from normal growth to normal growth (staying in the same state).
Note that these are conditional probabilities — the probability of transitioning from one state to another (or staying at the same one) conditional on the current state.
To make the problem easier to work with numerically, let’s convert states to numbers.
In particular, we agree that
state 0 represents normal growth
state 1 represents mild recession
state 2 represents severe recession
Let \(X_t\) record the value of the state at time \(t\).
Now we can write the statement “there is a 14.5% probability of transitioning from mild recession to normal growth in one month” as
We can collect all of these conditional probabilities into a matrix, as follows
Notice that \(P\) is a stochastic matrix.
Now we have the following relationship
This holds for any \(i,j\) between 0 and 2.
In particular, \(P(i,j)\) is the probability of transitioning from state \(i\) to state \(j\) in one month.
35.2.2.2. Example 2: Unemployment#
Consider a worker who, at any given time \(t\), is either unemployed (state 0) or employed (state 1).
Suppose that, over a one-month period,
the unemployed worker finds a job with probability \(\alpha \in (0, 1)\).
the employed worker loses her job and becomes unemployed with probability \(\beta \in (0, 1)\).
Given the above information, we can write out the transition probabilities in matrix form as
For example,
Suppose we can estimate the values \(\alpha\) and \(\beta\).
Then we can address a range of questions, such as
What is the average duration of unemployment?
Over the long-run, what fraction of the time does a worker find herself unemployed?
Conditional on employment, what is the probability of becoming unemployed at least once over the next 12 months?
We’ll cover some of these applications below.
35.2.2.3. Example 3: Political transition dynamics#
Imam and Temple [Imam and Temple, 2023] categorize political institutions into three types: democracy \(\text{(D)}\), autocracy \(\text{(A)}\), and an intermediate state called anocracy \(\text{(N)}\).
Each institution can have two potential development regimes: collapse \(\text{(C)}\) and growth \(\text{(G)}\). This results in six possible states: \(\text{DG, DC, NG, NC, AG}\) and \(\text{AC}\).
Imam and Temple [Imam and Temple, 2023] estimate the following transition probabilities:
nodes = ['DG', 'DC', 'NG', 'NC', 'AG', 'AC']
P = [[0.86, 0.11, 0.03, 0.00, 0.00, 0.00],
[0.52, 0.33, 0.13, 0.02, 0.00, 0.00],
[0.12, 0.03, 0.70, 0.11, 0.03, 0.01],
[0.13, 0.02, 0.35, 0.36, 0.10, 0.04],
[0.00, 0.00, 0.09, 0.11, 0.55, 0.25],
[0.00, 0.00, 0.09, 0.15, 0.26, 0.50]]
Here is a visualization, with darker colors indicating higher probability.
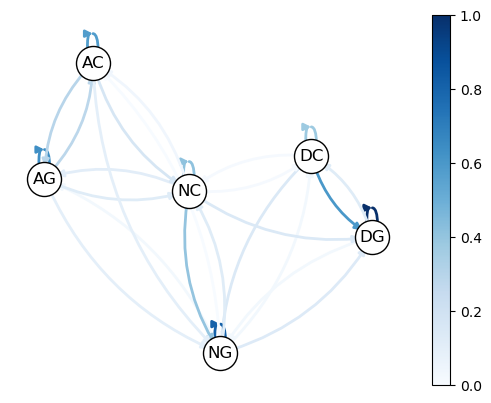
The probabilities can be represented in matrix form as follows
Looking at the data, we see that democracies tend to have longer-lasting growth regimes compared to autocracies (as indicated by the lower probability of transitioning from growth to growth in autocracies).
We can also find a higher probability from collapse to growth in democratic regimes.
35.2.3. Defining Markov chains#
So far we’ve given examples of Markov chains but we haven’t defined them.
Let’s do that now.
To begin, let \(S\) be a finite set \(\{x_1, \ldots, x_n\}\) with \(n\) elements.
The set \(S\) is called the state space and \(x_1, \ldots, x_n\) are the state values.
A distribution \(\psi\) on \(S\) is a probability mass function of length \(n\), where \(\psi(i)\) is the amount of probability allocated to state \(x_i\).
A Markov chain \(\{X_t\}\) on \(S\) is a sequence of random variables taking values in \(S\) that have the Markov property.
This means that, for any time \(t\) and any state \(y \in S\),
This means that once we know the current state \(X_t\), adding knowledge of earlier states \(X_{t-1}, X_{t-2}\) provides no additional information about probabilities of future states.
Thus, the dynamics of a Markov chain are fully determined by the set of conditional probabilities
By construction,
\(P(x, y)\) is the probability of going from \(x\) to \(y\) in one unit of time (one step)
\(P(x, \cdot)\) is the conditional distribution (probability mass function) of \(X_{t+1}\) given \(X_t = x\)
We can view \(P\) as a stochastic matrix where
Going the other way, if we take a stochastic matrix \(P\), we can generate a Markov chain \(\{X_t\}\) as follows:
draw \(X_0\) from a distribution \(\psi_0\) on \(S\)
for each \(t = 0, 1, \ldots\), draw \(X_{t+1}\) from \(P(X_t,\cdot)\)
By construction, the resulting process satisfies (35.3).
35.3. Simulation#
A good way to study Markov chains is to simulate them.
Let’s start by doing this ourselves and then look at libraries that can help us.
In these exercises, we’ll take the state space to be \(S = 0,\ldots, n-1\).
(We start at \(0\) because Python arrays are indexed from \(0\).)
35.3.1. Writing our own simulation code#
To simulate a Markov chain, we need
a stochastic matrix \(P\) and
a probability mass function \(\psi_0\) of length \(n\) from which to draw an initial realization of \(X_0\).
The Markov chain is then constructed as follows:
At time \(t=0\), draw a realization of \(X_0\) from the distribution \(\psi_0\).
At each subsequent time \(t\), draw a realization of the new state \(X_{t+1}\) from \(P(X_t, \cdot)\).
(That is, draw from row \(X_t\) of \(P\).)
To implement this simulation procedure, we need a method for generating draws from a discrete distribution.
For this task, we’ll use random.draw from QuantEcon.py.
To use random.draw, we first need to convert the probability mass function
to a cumulative distribution
ψ_0 = (0.3, 0.7) # probabilities over {0, 1}
cdf = np.cumsum(ψ_0) # convert into cumulative distribution
qe.random.draw(cdf, 5) # generate 5 independent draws from ψ
array([0, 1, 0, 1, 0])
We’ll write our code as a function that accepts the following three arguments
A stochastic matrix
P.An initial distribution
ψ_0.A positive integer
ts_lengthrepresenting the length of the time series the function should return.
def mc_sample_path(P, ψ_0=None, ts_length=1_000):
# set up
P = np.asarray(P)
X = np.empty(ts_length, dtype=int)
# Convert each row of P into a cdf
P_dist = np.cumsum(P, axis=1) # Convert rows into cdfs
# draw initial state, defaulting to 0
if ψ_0 is not None:
X_0 = qe.random.draw(np.cumsum(ψ_0))
else:
X_0 = 0
# simulate
X[0] = X_0
for t in range(ts_length - 1):
X[t+1] = qe.random.draw(P_dist[X[t], :])
return X
Let’s see how it works using the small matrix
P = [[0.4, 0.6],
[0.2, 0.8]]
Here’s a short time series.
mc_sample_path(P, ψ_0=(1.0, 0.0), ts_length=10)
array([0, 1, 1, 1, 1, 1, 1, 1, 1, 1])
It can be proven that for a long series drawn from P, the fraction of the
sample that takes value 0 will be about 0.25.
(We will explain why later.)
Moreover, this is true regardless of the initial distribution from which \(X_0\) is drawn.
The following code illustrates this
X = mc_sample_path(P, ψ_0=(0.1, 0.9), ts_length=1_000_000)
np.mean(X == 0)
np.float64(0.250345)
You can try changing the initial distribution to confirm that the output is
always close to 0.25 (for the P matrix above).
35.3.2. Using QuantEcon’s routines#
QuantEcon.py has routines for handling Markov chains, including simulation.
Here’s an illustration using the same \(P\) as the preceding example
mc = qe.MarkovChain(P)
X = mc.simulate(ts_length=1_000_000)
np.mean(X == 0)
np.float64(0.250359)
The simulate routine is faster (because it is JIT compiled).
%time mc_sample_path(P, ts_length=1_000_000) # Our homemade code version
CPU times: user 2.21 s, sys: 2.65 ms, total: 2.21 s
Wall time: 2.21 s
array([0, 0, 1, ..., 0, 1, 1], shape=(1000000,))
%time mc.simulate(ts_length=1_000_000) # qe code version
CPU times: user 13.2 ms, sys: 2.91 ms, total: 16.1 ms
Wall time: 15.8 ms
array([1, 1, 1, ..., 0, 0, 1], shape=(1000000,))
35.3.2.1. Adding state values and initial conditions#
If we wish to, we can provide a specification of state values to MarkovChain.
These state values can be integers, floats, or even strings.
The following code illustrates
mc = qe.MarkovChain(P, state_values=('unemployed', 'employed'))
mc.simulate(ts_length=4, init='employed') # Start at employed initial state
array(['employed', 'employed', 'employed', 'unemployed'], dtype='<U10')
mc.simulate(ts_length=4, init='unemployed') # Start at unemployed initial state
array(['unemployed', 'unemployed', 'employed', 'unemployed'], dtype='<U10')
mc.simulate(ts_length=4) # Start at randomly chosen initial state
array(['employed', 'employed', 'employed', 'employed'], dtype='<U10')
If we want to see indices rather than state values as outputs, we can use
mc.simulate_indices(ts_length=4)
array([1, 0, 0, 1])
35.4. Distributions over time#
We learned that
\(\{X_t\}\) is a Markov chain with stochastic matrix \(P\)
the distribution of \(X_t\) is known to be \(\psi_t\)
What then is the distribution of \(X_{t+1}\), or, more generally, of \(X_{t+m}\)?
To answer this, we let \(\psi_t\) be the distribution of \(X_t\) for \(t = 0, 1, 2, \ldots\).
Our first aim is to find \(\psi_{t + 1}\) given \(\psi_t\) and \(P\).
To begin, pick any \(y \in S\).
To get the probability of being at \(y\) tomorrow (at \(t+1\)), we account for all ways this can happen and sum their probabilities.
This leads to
(We are using the law of total probability.)
Rewriting this statement in terms of marginal and conditional probabilities gives
There are \(n\) such equations, one for each \(y \in S\).
If we think of \(\psi_{t+1}\) and \(\psi_t\) as row vectors, these \(n\) equations are summarized by the matrix expression
Thus, we postmultiply by \(P\) to move a distribution forward one unit of time.
By postmultiplying \(m\) times, we move a distribution forward \(m\) steps into the future.
Hence, iterating on (35.4), the expression \(\psi_{t+m} = \psi_t P^m\) is also valid — here \(P^m\) is the \(m\)-th power of \(P\).
As a special case, we see that if \(\psi_0\) is the initial distribution from which \(X_0\) is drawn, then \(\psi_0 P^m\) is the distribution of \(X_m\).
This is very important, so let’s repeat it
The general rule is that postmultiplying a distribution by \(P^m\) shifts it forward \(m\) units of time.
Hence the following is also valid.
35.4.1. Multiple step transition probabilities#
We know that the probability of transitioning from \(x\) to \(y\) in one step is \(P(x,y)\).
It turns out that the probability of transitioning from \(x\) to \(y\) in \(m\) steps is \(P^m(x,y)\), the \((x,y)\)-th element of the \(m\)-th power of \(P\).
To see why, consider again (35.6), but now with a \(\psi_t\) that puts all probability on state \(x\).
Then \(\psi_t\) is a vector with \(1\) in position \(x\) and zero elsewhere.
Inserting this into (35.6), we see that, conditional on \(X_t = x\), the distribution of \(X_{t+m}\) is the \(x\)-th row of \(P^m\).
In particular
Example 35.1 (Probability of Recession)
Recall the stochastic matrix \(P\) for recession and growth considered in Example 1: Economic states.
Suppose that the current state is unknown — perhaps statistics are available only at the end of the current month.
We guess that the probability that the economy is in state \(x\) is \(\psi_t(x)\) at time \(t\).
The probability of being in recession (either mild or severe) in 6 months’ time is given by
Example 35.2 (Cross-Sectional Distributions)
The distributions we have been studying can be viewed either
as probabilities or
as cross-sectional frequencies that the law of large numbers leads us to anticipate for large samples.
To illustrate, recall our model of employment/unemployment dynamics for a given worker discussed in Example 2: Unemployment.
Consider a large population of workers, each of whose lifetime experience is described by the specified dynamics, with each worker’s outcomes being realizations of processes that are statistically independent of all other workers’ processes.
Let \(\psi_t\) be the current cross-sectional distribution over \(\{ 0, 1 \}\).
The cross-sectional distribution records fractions of workers employed and unemployed at a given moment \(t\).
For example, \(\psi_t(0)\) is the unemployment rate at time \(t\).
What will the cross-sectional distribution be in 10 periods hence?
The answer is \(\psi_t P^{10}\), where \(P\) is the stochastic matrix in (35.1).
This is because each worker’s state evolves according to \(P\), so \(\psi_t P^{10}\) is a marginal distribution for a single randomly selected worker.
But when the sample is large, outcomes and probabilities are roughly equal (by an application of the law of large numbers).
So for a very large (tending to infinite) population, \(\psi_t P^{10}\) also represents fractions of workers in each state.
This is exactly the cross-sectional distribution.
Note
A cross-sectional frequency measures how a particular variable (e.g., employment status) is distributed across a population at a specific time, providing information on the proportions of individuals in each possible state of that variable.
35.5. Stationary distributions#
As seen in (35.4), we can shift a distribution forward one unit of time via postmultiplication by \(P\).
Some distributions are invariant under this updating process — for example,
P = np.array([[0.4, 0.6],
[0.2, 0.8]])
ψ = (0.25, 0.75)
ψ @ P
array([0.25, 0.75])
Notice that ψ @ P is the same as ψ.
Such distributions are called stationary or invariant.
Formally, a distribution \(\psi^*\) on \(S\) is called stationary for \(P\) if \(\psi^* P = \psi^* \).
Notice that, postmultiplying by \(P\), we have \(\psi^* P^2 = \psi^* P = \psi^*\).
Continuing in the same way leads to \(\psi^* = \psi^* P^t\) for all \(t \ge 0\).
This tells us an important fact: If the distribution of \(\psi_0\) is a stationary distribution, then \(\psi_t\) will have this same distribution for all \(t \ge 0\).
The following theorem is proved in Chapter 4 of [Sargent and Stachurski, 2023] and numerous other sources.
Theorem 35.1
Every stochastic matrix \(P\) has at least one stationary distribution.
Note that there can be many stationary distributions corresponding to a given stochastic matrix \(P\).
For example, if \(P\) is the identity matrix, then all distributions on \(S\) are stationary.
To get uniqueness, we need the Markov chain to “mix around,” so that the state doesn’t get stuck in some part of the state space.
This gives some intuition for the following theorem.
Theorem 35.2
If \(P\) is everywhere positive, then \(P\) has exactly one stationary distribution.
We will come back to this when we introduce irreducibility in the next lecture on Markov chains.
Example 35.3 (Steady-State Unemployment Probability)
Recall our model of the employment/unemployment dynamics of a particular worker discussed in Example 2: Unemployment.
If \(\alpha \in (0,1)\) and \(\beta \in (0,1)\), then the transition matrix is everywhere positive.
Let \(\psi^* = (p, 1-p)\) be the stationary distribution, so that \(p\) corresponds to unemployment (state 0).
Using \(\psi^* = \psi^* P\) and a bit of algebra yields
This is, in some sense, a steady state probability of unemployment.
Not surprisingly it tends to zero as \(\beta \to 0\), and to one as \(\alpha \to 0\).
35.5.1. Calculating stationary distributions#
A stable algorithm for computing stationary distributions is implemented in QuantEcon.py.
Here’s an example
P = [[0.4, 0.6],
[0.2, 0.8]]
mc = qe.MarkovChain(P)
mc.stationary_distributions # Show all stationary distributions
array([[0.25, 0.75]])
35.5.2. Asymptotic stationarity#
Consider an everywhere positive stochastic matrix with unique stationary distribution \(\psi^*\).
Sometimes the distribution \(\psi_t = \psi_0 P^t\) of \(X_t\) converges to \(\psi^*\) regardless of \(\psi_0\).
For example, we have the following result
Theorem 35.3
If there exists an integer \(m\) such that all entries of \(P^m\) are strictly positive, then
where \(\psi^*\) is the unique stationary distribution.
This situation is often referred to as asymptotic stationarity or global stability.
A proof of the theorem can be found in Chapter 4 of [Sargent and Stachurski, 2023], as well as many other sources.
35.5.2.1. Example: Hamilton’s chain#
Hamilton’s chain satisfies the conditions of the theorem because \(P^2\) is everywhere positive:
P = np.array([[0.971, 0.029, 0.000],
[0.145, 0.778, 0.077],
[0.000, 0.508, 0.492]])
P @ P
array([[0.947046, 0.050721, 0.002233],
[0.253605, 0.648605, 0.09779 ],
[0.07366 , 0.64516 , 0.28118 ]])
Let’s pick an initial distribution \(\psi_1, \psi_2, \psi_3\) and trace out the sequence of distributions \(\psi_i P^t\) for \(t = 0, 1, 2, \ldots\), for \(i=1, 2, 3\).
First, we write a function to iterate the sequence of distributions for ts_length period
def iterate_ψ(ψ_0, P, ts_length):
n = len(P)
ψ_t = np.empty((ts_length, n))
ψ_t[0 ]= ψ_0
for t in range(1, ts_length):
ψ_t[t] = ψ_t[t-1] @ P
return ψ_t
Now we plot the sequence
Here
\(P\) is the stochastic matrix for recession and growth considered in Example 1: Economic states.
The red, blue and green dots are initial marginal probability distributions \(\psi_1, \psi_2, \psi_3\), each of which is represented as a vector in \(\mathbb R^3\).
The transparent dots are the marginal distributions \(\psi_i P^t\) for \(t = 1, 2, \ldots\), for \(i=1,2,3.\)
The yellow dot is \(\psi^*\).
You might like to try experimenting with different initial conditions.
35.5.2.2. Example: failure of convergence#
Consider the periodic chain with stochastic matrix
This matrix does not satisfy the conditions of strict_stationary because, as you can readily check,
\(P^m = P\) when \(m\) is odd and
\(P^m = I\), the identity matrix, when \(m\) is even.
Hence there is no \(m\) such that all elements of \(P^m\) are strictly positive.
Moreover, we can see that global stability does not hold.
For instance, if we start at \(\psi_0 = (1,0)\), then \(\psi_m = \psi_0 P^m\) is \((1, 0)\) when \(m\) is even and \((0,1)\) when \(m\) is odd.
We can see similar phenomena in higher dimensions.
The next figure illustrates this for a periodic Markov chain with three states.
This animation demonstrates the behavior of an irreducible and periodic stochastic matrix.
The red, yellow, and green dots represent different initial probability distributions.
The blue dot represents the unique stationary distribution.
Unlike Hamilton’s Markov chain, these initial distributions do not converge to the unique stationary distribution.
Instead, they cycle periodically around the probability simplex, illustrating that asymptotic stability fails.
35.6. Computing expectations#
We sometimes want to compute mathematical expectations of functions of \(X_t\) of the form
and conditional expectations such as
where
\(\{X_t\}\) is a Markov chain generated by \(n \times n\) stochastic matrix \(P\).
\(h\) is a given function, which, in terms of matrix algebra, we’ll think of as the column vector
Computing the unconditional expectation (35.7) is easy.
We just sum over the marginal distribution of \(X_t\) to get
Here \(\psi\) is the distribution of \(X_0\).
Since \(\psi\) and hence \(\psi P^t\) are row vectors, we can also write this as
For the conditional expectation (35.8), we need to sum over the conditional distribution of \(X_{t + k}\) given \(X_t = x\).
We already know that this is \(P^k(x, \cdot)\), so
35.6.1. Expectations of geometric sums#
Sometimes we want to compute the mathematical expectation of a geometric sum, such as \(\sum_t \beta^t h(X_t)\).
In view of the preceding discussion, this is
By the Neumann series lemma, this sum can be calculated using
The vector \(P^k h\) stores the conditional expectation \(\mathbb E [ h(X_{t + k}) \mid X_t = x]\) over all \(x\).
Exercise 35.1
Imam and Temple [Imam and Temple, 2023] used a three-state transition matrix to describe the transition of three states of a regime: growth, stagnation, and collapse
where rows, from top to down, correspond to growth, stagnation, and collapse.
In this exercise,
visualize the transition matrix and show this process is asymptotically stationary
calculate the stationary distribution using matrix powers and QuantEcon package
visualize the dynamics of \((\psi_0 P^t)(i)\) where \(t \in 0, ..., 25\) and compare the convergent path with the previous transition matrix
Compare your solution to the paper.
Solution to Exercise 35.1
Solution 1:
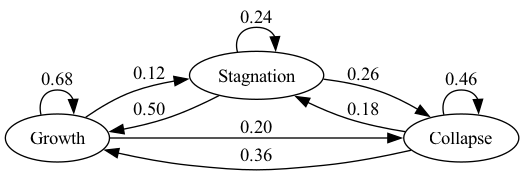
Since the matrix is everywhere positive, there is a unique stationary distribution \(\psi^*\) such that \(\psi_t\to \psi^*\) as \(t\to \infty\).
Solution 2:
One simple way to calculate the stationary distribution is to take the power of the transition matrix as we have shown before
P = np.array([[0.68, 0.12, 0.20],
[0.50, 0.24, 0.26],
[0.36, 0.18, 0.46]])
P_power = np.linalg.matrix_power(P, 20)
P_power
array([[0.56145769, 0.15565164, 0.28289067],
[0.56145769, 0.15565164, 0.28289067],
[0.56145769, 0.15565164, 0.28289067]])
Note that rows of the transition matrix converge to the stationary distribution.
ψ_star_p = P_power[0]
ψ_star_p
array([0.56145769, 0.15565164, 0.28289067])
mc = qe.MarkovChain(P)
ψ_star = mc.stationary_distributions[0]
ψ_star
array([0.56145769, 0.15565164, 0.28289067])
Exercise 35.2
We discussed the six-state transition matrix estimated by Imam & Temple [Imam and Temple, 2023] before.
nodes = ['DG', 'DC', 'NG', 'NC', 'AG', 'AC']
P = [[0.86, 0.11, 0.03, 0.00, 0.00, 0.00],
[0.52, 0.33, 0.13, 0.02, 0.00, 0.00],
[0.12, 0.03, 0.70, 0.11, 0.03, 0.01],
[0.13, 0.02, 0.35, 0.36, 0.10, 0.04],
[0.00, 0.00, 0.09, 0.11, 0.55, 0.25],
[0.00, 0.00, 0.09, 0.15, 0.26, 0.50]]
In this exercise,
show this process is asymptotically stationary without simulation
simulate and visualize the dynamics starting with a uniform distribution across states (each state will have a probability of 1/6)
change the initial distribution to P(DG) = 1, while all other states have a probability of 0
Solution to Exercise 35.2
Solution 1:
Although \(P\) is not everywhere positive, \(P^m\) when \(m=3\) is everywhere positive.
P = np.array([[0.86, 0.11, 0.03, 0.00, 0.00, 0.00],
[0.52, 0.33, 0.13, 0.02, 0.00, 0.00],
[0.12, 0.03, 0.70, 0.11, 0.03, 0.01],
[0.13, 0.02, 0.35, 0.36, 0.10, 0.04],
[0.00, 0.00, 0.09, 0.11, 0.55, 0.25],
[0.00, 0.00, 0.09, 0.15, 0.26, 0.50]])
np.linalg.matrix_power(P,3)
array([[0.764927, 0.133481, 0.085949, 0.011481, 0.002956, 0.001206],
[0.658861, 0.131559, 0.161367, 0.031703, 0.011296, 0.005214],
[0.291394, 0.057788, 0.439702, 0.113408, 0.062707, 0.035001],
[0.272459, 0.051361, 0.365075, 0.132207, 0.108152, 0.070746],
[0.064129, 0.012533, 0.232875, 0.154385, 0.299243, 0.236835],
[0.072865, 0.014081, 0.244139, 0.160905, 0.265846, 0.242164]])
So it satisfies the requirement.
Solution 2:
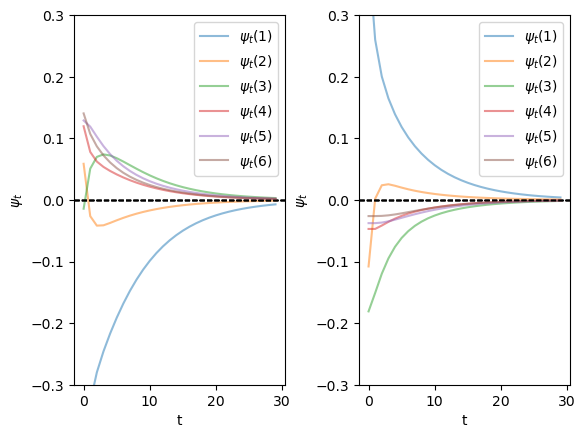
We find the distribution \(\psi\) converges to the stationary distribution quickly regardless of the initial distributions
ts_length = 30
num_distributions = 20
nodes = ['DG', 'DC', 'NG', 'NC', 'AG', 'AC']
# Get parameters of transition matrix
n = len(P)
mc = qe.MarkovChain(P)
ψ_star = mc.stationary_distributions[0]
ψ_0 = np.array([[1/6 for i in range(6)],
[0 if i != 0 else 1 for i in range(6)]])
## Draw the plot
fig, axes = plt.subplots(ncols=2)
plt.subplots_adjust(wspace=0.35)
for idx in range(2):
ψ_t = iterate_ψ(ψ_0[idx], P, ts_length)
for i in range(n):
axes[idx].plot(ψ_t[:, i] - ψ_star[i], alpha=0.5, label=fr'$\psi_t({i+1})$')
axes[idx].set_ylim([-0.3, 0.3])
axes[idx].set_xlabel('t')
axes[idx].set_ylabel(fr'$\psi_t$')
axes[idx].legend()
axes[idx].axhline(0, linestyle='dashed', lw=1, color = 'black')
plt.show()
Exercise 35.3
Prove the following: If \(P\) is a stochastic matrix, then so is the \(k\)-th power \(P^k\) for all \(k \in \mathbb N\).
Solution to Exercise 35.3
Suppose that \(P\) is stochastic and, moreover, that \(P^k\) is stochastic for some integer \(k\).
We will prove that \(P^{k+1} = P P^k\) is also stochastic.
(We are doing proof by induction — we assume the claim is true at \(k\) and now prove it is true at \(k+1\).)
To see this, observe that, since \(P^k\) is stochastic and the product of nonnegative matrices is nonnegative, \(P^{k+1} = P P^k\) is nonnegative.
Also, if \(\mathbf 1\) is a column vector of ones, then, since \(P^k\) is stochastic we have \(P^k \mathbf 1 = \mathbf 1\) (rows sum to one).
Therefore \(P^{k+1} \mathbf 1 = P P^k \mathbf 1 = P \mathbf 1 = \mathbf 1\)
The proof is done.