18. Computing Square Roots#
18.1. Introduction#
Chapter 24 of [Russell, 2004] about early Greek mathematics and astronomy contains this fascinating passage:
The square root of 2, which was the first irrational to be discovered, was known to the early Pythagoreans, and ingenious methods of approximating to its value were discovered. The best was as follows: Form two columns of numbers, which we will call the \(a\)’s and the \(b\)’s; each starts with a \(1\). The next \(a\), at each stage, is formed by adding the last \(a\) and the \(b\) already obtained; the next \(b\) is formed by adding twice the previous \(a\) to the previous \(b\). The first 6 pairs so obtained are \((1,1), (2,3), (5,7), (12,17), (29,41), (70,99)\). In each pair, \(2 a^2 - b^2\) is \(1\) or \(-1\). Thus \(b/a\) is nearly the square root of two, and at each fresh step it gets nearer. For instance, the reader may satisfy himself that the square of \(99/70\) is very nearly equal to \(2\).
This lecture drills down and studies this ancient method for computing square roots by using some of the matrix algebra that we’ve learned in earlier quantecon lectures.
In particular, this lecture can be viewed as a sequel to Eigenvalues and Eigenvectors.
It provides an example of how eigenvectors isolate invariant subspaces that help construct and analyze solutions of linear difference equations.
When vector \(x_t\) starts in an invariant subspace, iterating the difference equation keeps \(x_{t+j}\) in that subspace for all \(j \geq 1\).
Invariant subspace methods are used throughout applied economic dynamics, for example, in the lecture Money Financed Government Deficits and Price Levels.
Our approach here is to illustrate the method with an ancient example, one that ancient Greek mathematicians used to compute square roots of positive integers.
18.2. Perfect squares and irrational numbers#
An integer is called a perfect square if its square root is also an integer.
An ordered sequence of perfect squares starts with
If an integer is not a perfect square, then its square root is an irrational number – i.e., it cannot be expressed as a ratio of two integers, and its decimal expansion is indefinite.
The ancient Greeks invented an algorithm to compute square roots of integers, including integers that are not perfect squares.
Their method involved
computing a particular sequence of integers \(\{y_t\}_{t=0}^\infty\);
computing \(\lim_{t \rightarrow \infty} \left(\frac{y_{t+1}}{y_t}\right) = \bar r\);
deducing the desired square root from \(\bar r\).
In this lecture, we’ll describe this method.
We’ll also use invariant subspaces to describe variations on this method that are faster.
18.3. Second-order linear difference equations#
Before telling how the ancient Greeks computed square roots, we’ll provide a quick introduction to second-order linear difference equations.
We’ll study the following second-order linear difference equation
where \((y_{-1}, y_{-2})\) is a pair of given initial conditions.
Equation (18.1) is actually an infinite number of linear equations in the sequence \(\{y_t\}_{t=0}^\infty\).
There is one equation each for \(t = 0, 1, 2, \ldots\).
We could follow an approach taken in the lecture on present values and stack all of these equations into a single matrix equation that we would then solve by using matrix inversion.
Note
In the present instance, the matrix equation would multiply a countably infinite dimensional square matrix by a countably infinite dimensional vector. With some qualifications, matrix multiplication and inversion tools apply to such an equation.
But we won’t pursue that approach here.
Instead, we’ll seek to find a time-invariant function that solves our difference equation, meaning that it provides a formula for a \(\{y_t\}_{t=0}^\infty\) sequence that satisfies equation (18.1) for each \(t \geq 0\).
We seek an expression for \(y_t, t \geq 0\) as functions of the initial conditions \((y_{-1}, y_{-2})\):
We call such a function \(g\) a solution of the difference equation (18.1).
One way to discover a solution is to use a guess and verify method.
We shall begin by considering a special initial pair of initial conditions that satisfy
where \(\delta\) is a scalar to be determined.
For initial conditions that satisfy (18.3) equation (18.1) implies that
We want
which we can rewrite as the characteristic equation
Applying the quadratic formula to solve for the roots of (18.6) we find that
For either of the two \(\delta\)’s that satisfy equation (18.7), a solution of difference equation (18.1) is
provided that we set
The general solution of difference equation (18.1) takes the form
where \(\delta_1, \delta_2\) are the two solutions (18.7) of the characteristic equation (18.6), and \(\eta_1, \eta_2\) are two constants chosen to satisfy
or
Sometimes we are free to choose the initial conditions \((y_{-1}, y_{-2})\), in which case we use system (18.10) to find the associated \((\eta_1, \eta_2)\).
If we choose \((y_{-1}, y_{-2})\) to set \((\eta_1, \eta_2) = (1, 0)\), then \(y_t = \delta_1^t\) for all \(t \geq 0\).
If we choose \((y_{-1}, y_{-2})\) to set \((\eta_1, \eta_2) = (0, 1)\), then \(y_t = \delta_2^t\) for all \(t \geq 0\).
Soon we’ll relate the preceding calculations to components of an eigen decomposition of a transition matrix that represents difference equation (18.1) in a very convenient way.
We’ll turn to that after we describe how Ancient Greeks figured out how to compute square roots of positive integers that are not perfect squares.
18.4. Algorithm of the Ancient Greeks#
Let \(\sigma\) be a positive integer greater than \(1\).
So \(\sigma \in {\mathcal I} \equiv \{2, 3, \ldots \}\).
We want an algorithm to compute the square root of \(\sigma \in {\mathcal I}\).
If \(\sqrt{\sigma} \in {\mathcal I}\), \(\sigma \) is said to be a perfect square.
If \(\sqrt{\sigma} \not\in {\mathcal I}\), it turns out that it is irrational.
Ancient Greeks used a recursive algorithm to compute square roots of integers that are not perfect squares.
The algorithm iterates on a second-order linear difference equation in the sequence \(\{y_t\}_{t=0}^\infty\):
together with a pair of integers that are initial conditions for \(y_{-1}, y_{-2}\).
First, we’ll deploy some techniques for solving the difference equations that are also deployed in Samuelson Multiplier-Accelerator.
The characteristic equation associated with difference equation (18.12) is
(Notice how this is an instance of equation (18.6) above.)
Factoring the right side of equation (18.13), we obtain
where
for \(x = \lambda_1\) or \(x = \lambda_2\).
These two special values of \(x\) are sometimes called zeros or roots of \(c(x)\).
By applying the quadratic formula to solve for the roots the characteristic equation (18.13), we find that
Formulas (18.15) indicate that \(\lambda_1\) and \(\lambda_2\) are each functions of a single variable, namely, \(\sqrt{\sigma}\), the object that we along with some Ancient Greeks want to compute.
Ancient Greeks had an indirect way of exploiting this fact to compute square roots of a positive integer.
They did this by starting from particular initial conditions \(y_{-1}, y_{-2}\) and iterating on the difference equation (18.12).
Solutions of difference equation (18.12) take the form
where \(\eta_1\) and \(\eta_2\) are chosen to satisfy prescribed initial conditions \(y_{-1}, y_{-2}\):
System (18.16) of simultaneous linear equations will play a big role in the remainder of this lecture.
Since \(\lambda_1 = 1 + \sqrt{\sigma} > 1 > \lambda_2 = 1 - \sqrt{\sigma} \), it follows that for almost all (but not all) initial conditions
Thus,
However, notice that if \(\eta_1 = 0\), then
so that
Actually, if \(\eta_1 =0\), it follows that
so that convergence is immediate and there is no need to take limits.
Symmetrically, if \(\eta_2 =0\), it follows that
so again, convergence is immediate, and we have no need to compute a limit.
System (18.16) of simultaneous linear equations can be used in various ways.
we can take \(y_{-1}, y_{-2}\) as given initial conditions and solve for \(\eta_1, \eta_2\);
we can instead take \(\eta_1, \eta_2\) as given and solve for initial conditions \(y_{-1}, y_{-2}\).
Notice how we used the second approach above when we set \(\eta_1, \eta_2\) either to \((0, 1)\), for example, or \((1, 0)\), for example.
In taking this second approach, we constructed an invariant subspace of \({\bf R}^2\).
Here is what is going on.
For \( t \geq 0\) and for most pairs of initial conditions \((y_{-1}, y_{-2}) \in {\bf R}^2\) for equation (18.12), \(y_t\) can be expressed as a linear combination of \(y_{t-1}\) and \(y_{t-2}\).
But for some special initial conditions \((y_{-1}, y_{-2}) \in {\bf R}^2\), \(y_t\) can be expressed as a linear function of \(y_{t-1}\) only.
These special initial conditions require that \(y_{-1}\) be a linear function of \(y_{-2}\).
We’ll study these special initial conditions soon.
But first let’s write some Python code to iterate on equation (18.12) starting from an arbitrary \((y_{-1}, y_{-2}) \in {\bf R}^2\).
18.5. Implementation#
We now implement the above algorithm to compute the square root of \(\sigma\).
In this lecture, we use the following import:
import numpy as np
import matplotlib.pyplot as plt
def solve_λs(coefs):
# Calculate the roots using numpy.roots
λs = np.roots(coefs)
# Sort the roots for consistency
return sorted(λs, reverse=True)
def solve_η(λ_1, λ_2, y_neg1, y_neg2):
# Solve the system of linear equation
A = np.array([
[1/λ_1, 1/λ_2],
[1/(λ_1**2), 1/(λ_2**2)]
])
b = np.array((y_neg1, y_neg2))
ηs = np.linalg.solve(A, b)
return ηs
def solve_sqrt(σ, coefs, y_neg1, y_neg2, t_max=100):
# Ensure σ is greater than 1
if σ <= 1:
raise ValueError("σ must be greater than 1")
# Characteristic roots
λ_1, λ_2 = solve_λs(coefs)
# Solve for η_1 and η_2
η_1, η_2 = solve_η(λ_1, λ_2, y_neg1, y_neg2)
# Compute the sequence up to t_max
t = np.arange(t_max + 1)
y = (λ_1 ** t) * η_1 + (λ_2 ** t) * η_2
# Compute the ratio y_{t+1} / y_t for large t
sqrt_σ_estimate = (y[-1] / y[-2]) - 1
return sqrt_σ_estimate
# Use σ = 2 as an example
σ = 2
# Encode characteristic equation
coefs = (1, -2, (1 - σ))
# Solve for the square root of σ
sqrt_σ = solve_sqrt(σ, coefs, y_neg1=2, y_neg2=1)
# Calculate the deviation
dev = abs(sqrt_σ-np.sqrt(σ))
print(f"sqrt({σ}) is approximately {sqrt_σ:.5f} (error: {dev:.5f})")
sqrt(2) is approximately 1.41421 (error: 0.00000)
Now we consider cases where \((\eta_1, \eta_2) = (0, 1)\) and \((\eta_1, \eta_2) = (1, 0)\)
# Compute λ_1, λ_2
λ_1, λ_2 = solve_λs(coefs)
print(f'Roots for the characteristic equation are ({λ_1:.5f}, {λ_2:.5f}))')
Roots for the characteristic equation are (2.41421, -0.41421))
# Case 1: η_1, η_2 = (0, 1)
ηs = (0, 1)
# Compute y_{t} and y_{t-1} with t >= 0
y = lambda t, ηs: (λ_1 ** t) * ηs[0] + (λ_2 ** t) * ηs[1]
sqrt_σ = 1 - y(1, ηs) / y(0, ηs)
print(f"For η_1, η_2 = (0, 1), sqrt_σ = {sqrt_σ:.5f}")
For η_1, η_2 = (0, 1), sqrt_σ = 1.41421
# Case 2: η_1, η_2 = (1, 0)
ηs = (1, 0)
sqrt_σ = y(1, ηs) / y(0, ηs) - 1
print(f"For η_1, η_2 = (1, 0), sqrt_σ = {sqrt_σ:.5f}")
For η_1, η_2 = (1, 0), sqrt_σ = 1.41421
We find that convergence is immediate.
Next, we’ll represent the preceding analysis by first vectorizing our second-order difference equation (18.12) and then using eigendecompositions of an associated state transition matrix.
18.6. Vectorizing the difference equation#
Represent (18.12) with the first-order matrix difference equation
or
where
Construct an eigendecomposition of \(M\):
where columns of \(V\) are eigenvectors corresponding to eigenvalues \(\lambda_1\) and \(\lambda_2\).
The eigenvalues can be ordered so that \(\lambda_1 > 1 > \lambda_2\).
Write equation (18.12) as
Now we implement the algorithm above.
First we write a function that iterates \(M\)
def iterate_M(x_0, M, num_steps, dtype=np.float64):
# Eigendecomposition of M
Λ, V = np.linalg.eig(M)
V_inv = np.linalg.inv(V)
# Initialize the array to store results
xs = np.zeros((x_0.shape[0],
num_steps + 1))
# Perform the iterations
xs[:, 0] = x_0
for t in range(num_steps):
xs[:, t + 1] = M @ xs[:, t]
return xs, Λ, V, V_inv
# Define the state transition matrix M
M = np.array([
[2, -(1 - σ)],
[1, 0]])
# Initial condition vector x_0
x_0 = np.array([2, 2])
# Perform the iteration
xs, Λ, V, V_inv = iterate_M(x_0, M, num_steps=100)
print(f"eigenvalues:\n{Λ}")
print(f"eigenvectors:\n{V}")
print(f"inverse eigenvectors:\n{V_inv}")
eigenvalues:
[ 2.41421356 -0.41421356]
eigenvectors:
[[ 0.92387953 -0.38268343]
[ 0.38268343 0.92387953]]
inverse eigenvectors:
[[ 0.92387953 0.38268343]
[-0.38268343 0.92387953]]
Let’s compare the eigenvalues to the roots (18.15) of equation (18.13) that we computed above.
roots = solve_λs((1, -2, (1 - σ)))
print(f"roots: {np.round(roots, 8)}")
roots: [ 2.41421356 -0.41421356]
Hence we confirmed (18.17).
Information about the square root we are after is also contained in the two eigenvectors.
Indeed, each eigenvector is just a two-dimensional subspace of \({\mathbb R}^3\) pinned down by dynamics of the form
that we encountered above in equation (18.8).
In equation (18.18), the \(i\)th \(\lambda_i\) equals the \(V_{i, 1}/V_{i,2}\).
The following graph verifies this for our example.
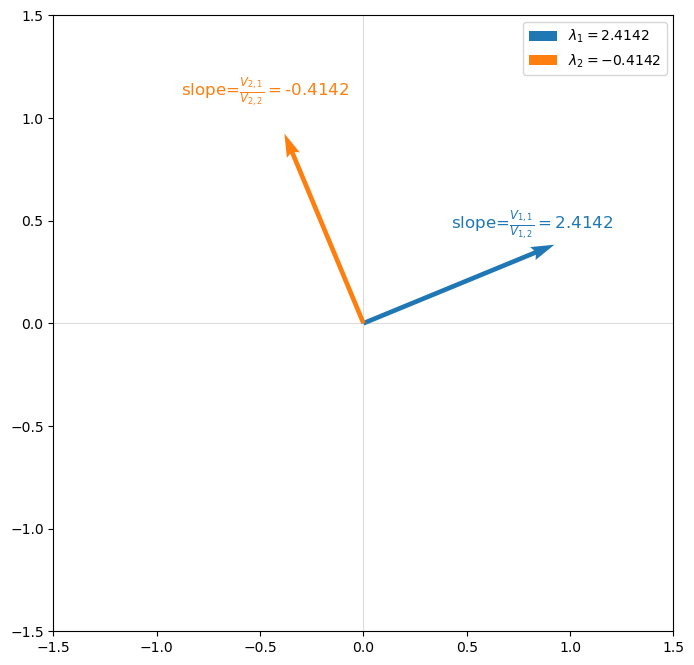
18.7. Invariant subspace approach#
The preceding calculation indicates that we can use the eigenvectors \(V\) to construct 2-dimensional invariant subspaces.
We’ll pursue that possibility now.
Define the transformed variables
Evidently, we can recover \(x_t\) from \(x_t^*\):
The following notations and equations will help us.
Let
Notice that it follows from
that
and
These equations will be very useful soon.
Notice that
To deactivate \(\lambda_1\) we want to set
This can be achieved by setting
To deactivate \(\lambda_2\), we want to set
This can be achieved by setting
Let’s verify (18.19) and (18.20) below
To deactivate \(\lambda_1\) we use (18.19)
xd_1 = np.array((x_0[0],
V[1,1]/V[0,1] * x_0[0]),
dtype=np.float64)
# Compute x_{1,0}^*
np.round(V_inv @ xd_1, 8)
array([-0. , -5.22625186])
We find \(x_{1,0}^* = 0\).
Now we deactivate \(\lambda_2\) using (18.20)
xd_2 = np.array((x_0[0],
V[1,0]/V[0,0] * x_0[0]),
dtype=np.float64)
# Compute x_{2,0}^*
np.round(V_inv @ xd_2, 8)
array([2.1647844, 0. ])
We find \(x_{2,0}^* = 0\).
# Simulate with muted λ1 λ2.
num_steps = 10
xs_λ1 = iterate_M(xd_1, M, num_steps)[0]
xs_λ2 = iterate_M(xd_2, M, num_steps)[0]
# Compute ratios y_t / y_{t-1}
ratios_λ1 = xs_λ1[1, 1:] / xs_λ1[1, :-1]
ratios_λ2 = xs_λ2[1, 1:] / xs_λ2[1, :-1]
The following graph shows the ratios \(y_t / y_{t-1}\) for the two cases.
We find that the ratios converge to \(\lambda_2\) in the first case and \(\lambda_1\) in the second case.
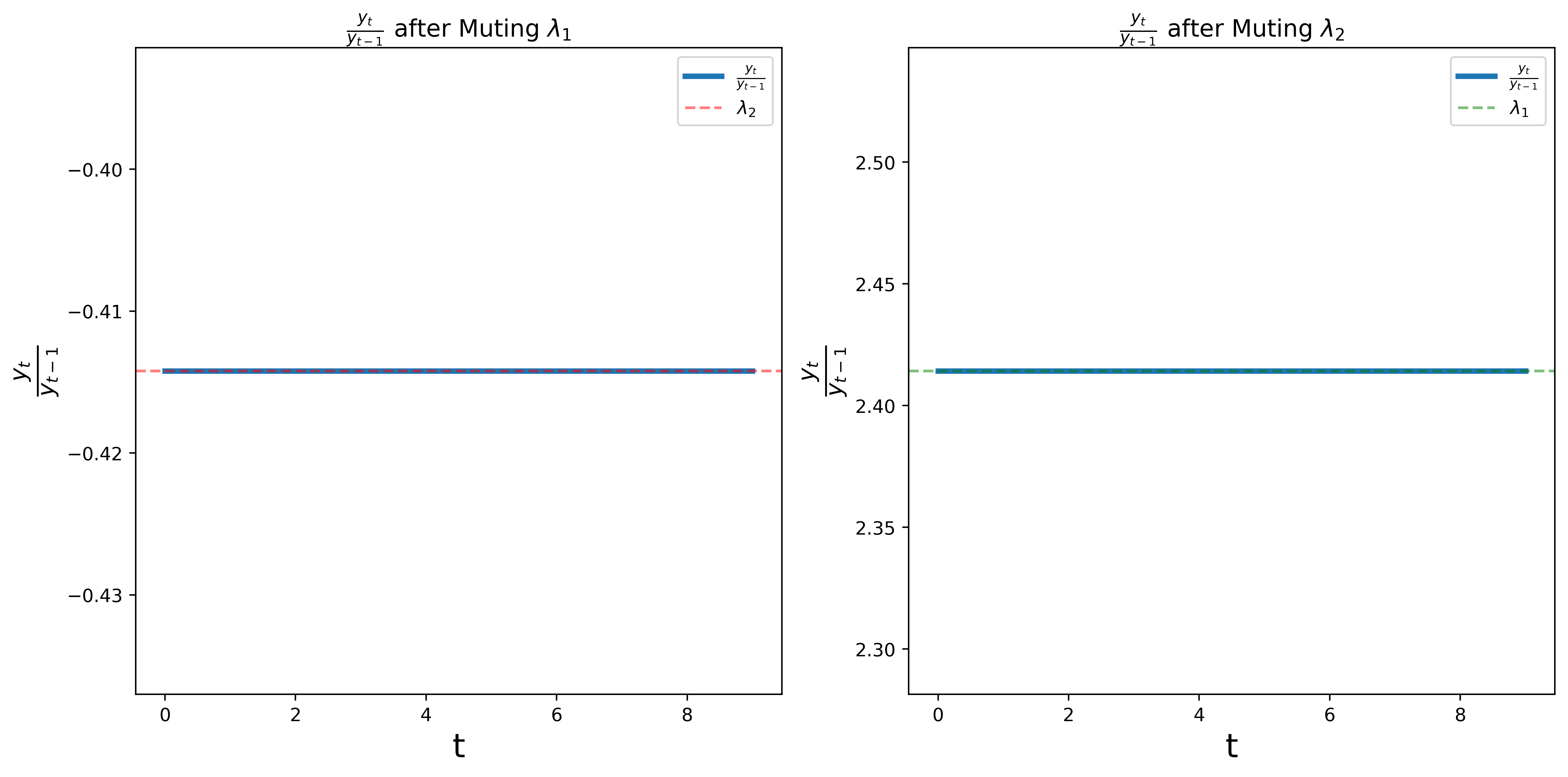
18.8. Concluding remarks#
This lecture sets the stage for many other applications of the invariant subspace methods.
All of these exploit very similar equations based on eigen decompositions.
We shall encounter equations very similar to (18.19) and (18.20) in Money Financed Government Deficits and Price Levels and in many other places in dynamic economic theory.
18.9. Exercise#
Exercise 18.1
Please use matrix algebra to formulate the method described by Bertrand Russell at the beginning of this lecture.
Define a state vector \(x_t = \begin{bmatrix} a_t \cr b_t \end{bmatrix}\).
Formulate a first-order vector difference equation for \(x_t\) of the form \(x_{t+1} = A x_t\) and compute the matrix \(A\).
Use the system \(x_{t+1} = A x_t\) to replicate the sequence of \(a_t\)’s and \(b_t\)’s described by Bertrand Russell.
Compute the eigenvectors and eigenvalues of \(A\) and compare them to corresponding objects computed in the text of this lecture.
Solution
Here is one solution.
According to the quote, we can formulate
with \(x_0 = \begin{bmatrix} a_0 \cr b_0 \end{bmatrix} = \begin{bmatrix} 1 \cr 1 \end{bmatrix}\)
By (18.21), we can write matrix \(A\) as
Then \(x_{t+1} = A x_t\) for \(t \in \{0, \dots, 5\}\)
# Define the matrix A
A = np.array([[1, 1],
[2, 1]])
# Initial vector x_0
x_0 = np.array([1, 1])
# Number of iterations
n = 6
# Generate the sequence
xs = np.array([x_0])
x_t = x_0
for _ in range(1, n):
x_t = A @ x_t
xs = np.vstack([xs, x_t])
# Print the sequence
for i, (a_t, b_t) in enumerate(xs):
print(f"Iter {i}: a_t = {a_t}, b_t = {b_t}")
# Compute eigenvalues and eigenvectors of A
eigenvalues, eigenvectors = np.linalg.eig(A)
print(f'\nEigenvalues:\n{eigenvalues}')
print(f'\nEigenvectors:\n{eigenvectors}')
Iter 0: a_t = 1, b_t = 1
Iter 1: a_t = 2, b_t = 3
Iter 2: a_t = 5, b_t = 7
Iter 3: a_t = 12, b_t = 17
Iter 4: a_t = 29, b_t = 41
Iter 5: a_t = 70, b_t = 99
Eigenvalues:
[ 2.41421356 -0.41421356]
Eigenvectors:
[[ 0.57735027 -0.57735027]
[ 0.81649658 0.81649658]]