22. Heavy-Tailed Distributions#
In addition to what’s in Anaconda, this lecture will need the following libraries:
!pip install --upgrade yfinance wbgapi
We use the following imports.
import matplotlib.pyplot as plt
import numpy as np
import yfinance as yf
import pandas as pd
import statsmodels.api as sm
import wbgapi as wb
from scipy.stats import norm, cauchy
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
22.1. Overview#
Heavy-tailed distributions are a class of distributions that generate “extreme” outcomes.
In the natural sciences (and in more traditional economics courses), heavy-tailed distributions are seen as quite exotic and non-standard.
However, it turns out that heavy-tailed distributions play a crucial role in economics.
In fact many – if not most – of the important distributions in economics are heavy-tailed.
In this lecture we explain what heavy tails are and why they are – or at least why they should be – central to economic analysis.
22.1.1. Introduction: light tails#
Most commonly used probability distributions in classical statistics and the natural sciences have “light tails.”
To explain this concept, let’s look first at examples.
Example 22.1
The classic example is the normal distribution, which has density
The two parameters \(\mu\) and \(\sigma\) are the mean and standard deviation respectively.
As \(x\) deviates from \(\mu\), the value of \(f(x)\) goes to zero extremely quickly.
We can see this when we plot the density and show a histogram of observations, as with the following code (which assumes \(\mu=0\) and \(\sigma=1\)).
fig, ax = plt.subplots()
X = norm.rvs(size=1_000_000)
ax.hist(X, bins=40, alpha=0.4, label='histogram', density=True)
x_grid = np.linspace(-4, 4, 400)
ax.plot(x_grid, norm.pdf(x_grid), label='density')
ax.legend()
plt.show()
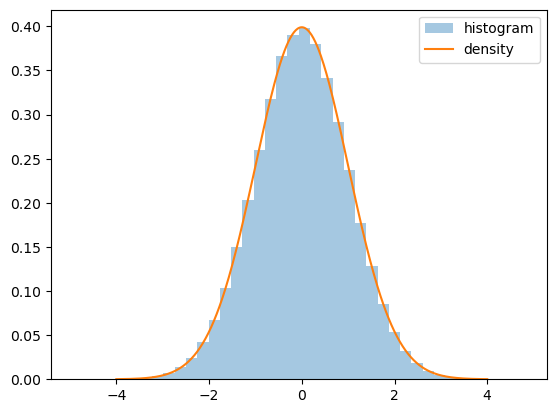
Fig. 22.1 Histogram of observations#
Notice how
the density’s tails converge quickly to zero in both directions and
even with 1,000,000 draws, we get no very large or very small observations.
We can see the last point more clearly by executing
X.min(), X.max()
(np.float64(-4.929200822775561), np.float64(4.796874035460447))
Here’s another view of draws from the same distribution:
n = 2000
fig, ax = plt.subplots()
data = norm.rvs(size=n)
ax.plot(list(range(n)), data, linestyle='', marker='o', alpha=0.5, ms=4)
ax.vlines(list(range(n)), 0, data, lw=0.2)
ax.set_ylim(-15, 15)
ax.set_xlabel('$i$')
ax.set_ylabel('$X_i$', rotation=0)
plt.show()
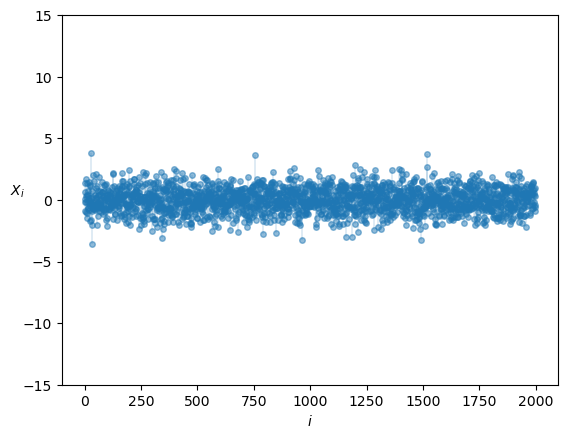
Fig. 22.2 Histogram of observations#
We have plotted each individual draw \(X_i\) against \(i\).
None are very large or very small.
In other words, extreme observations are rare and draws tend not to deviate too much from the mean.
Putting this another way, light-tailed distributions are those that rarely generate extreme values.
(A more formal definition is given below.)
Many statisticians and econometricians use rules of thumb such as “outcomes more than four or five standard deviations from the mean can safely be ignored.”
But this is only true when distributions have light tails.
22.1.2. When are light tails valid?#
In probability theory and in the real world, many distributions are light-tailed.
For example, human height is light-tailed.
Yes, it’s true that we see some very tall people.
For example, basketballer Sun Mingming is 2.32 meters tall
But have you ever heard of someone who is 20 meters tall? Or 200? Or 2000?
Have you ever wondered why not?
After all, there are 8 billion people in the world!
In essence, the reason we don’t see such draws is that the distribution of human height has very light tails.
In fact the distribution of human height obeys a bell-shaped curve similar to the normal distribution.
22.1.3. Returns on assets#
But what about economic data?
Let’s look at some financial data first.
Our aim is to plot the daily change in the price of Amazon (AMZN) stock for the period from 1st January 2015 to 1st July 2022.
This equates to daily returns if we set dividends aside.
The code below produces the desired plot using Yahoo financial data via the yfinance library.
data = yf.download('AMZN', '2015-1-1', '2022-7-1')
s = data['Close']
r = s.pct_change()
fig, ax = plt.subplots()
ax.plot(r, linestyle='', marker='o', alpha=0.5, ms=4)
ax.vlines(r.index, 0, r.values, lw=0.2)
ax.set_ylabel('returns', fontsize=12)
ax.set_xlabel('date', fontsize=12)
plt.show()
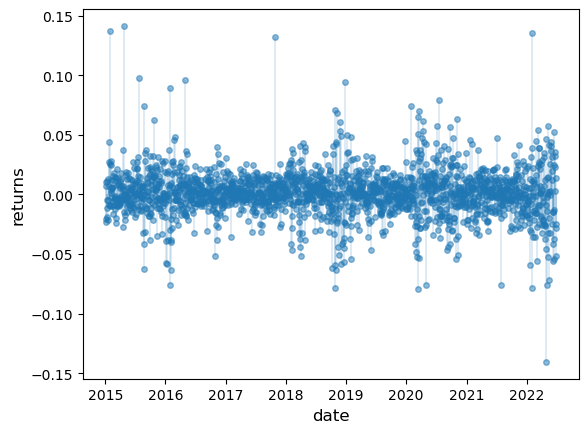
Fig. 22.3 Daily Amazon returns#
This data looks different to the draws from the normal distribution we saw above.
Several of observations are quite extreme.
We get a similar picture if we look at other assets, such as Bitcoin
data = yf.download('BTC-USD', '2015-1-1', '2022-7-1')
s = data['Close']
r = s.pct_change()
fig, ax = plt.subplots()
ax.plot(r, linestyle='', marker='o', alpha=0.5, ms=4)
ax.vlines(r.index, 0, r.values, lw=0.2)
ax.set_ylabel('returns', fontsize=12)
ax.set_xlabel('date', fontsize=12)
plt.show()
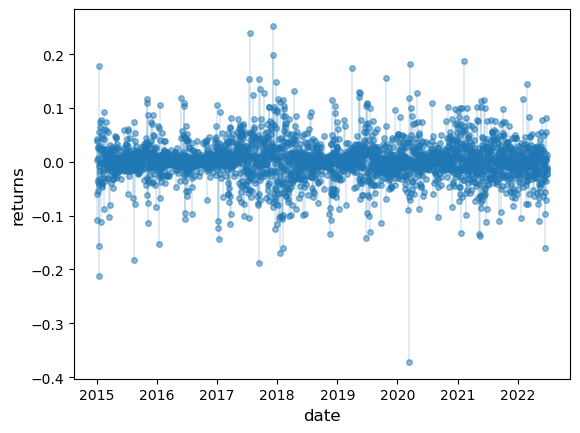
Fig. 22.4 Daily Bitcoin returns#
The histogram also looks different to the histogram of the normal distribution:
rng = np.random.default_rng()
r = rng.standard_t(df=5, size=1000)
fig, ax = plt.subplots()
ax.hist(r, bins=60, alpha=0.4, label='bitcoin returns', density=True)
xmin, xmax = plt.xlim()
x = np.linspace(xmin, xmax, 100)
p = norm.pdf(x, np.mean(r), np.std(r))
ax.plot(x, p, linewidth=2, label='normal distribution')
ax.set_xlabel('returns', fontsize=12)
ax.legend()
plt.show()
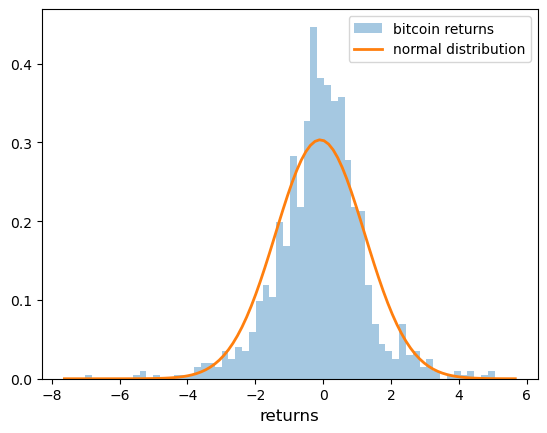
Fig. 22.5 Histogram (normal vs bitcoin returns)#
If we look at higher frequency returns data (e.g., tick-by-tick), we often see even more extreme observations.
See, for example, [Mandelbrot, 1963] or [Rachev, 2003].
22.1.4. Other data#
The data we have just seen is said to be “heavy-tailed”.
With heavy-tailed distributions, extreme outcomes occur relatively frequently.
Example 22.2
Importantly, there are many examples of heavy-tailed distributions observed in economic and financial settings!
For example, the income and the wealth distributions are heavy-tailed
You can imagine this: most people have low or modest wealth but some people are extremely rich.
The firm size distribution is also heavy-tailed
You can imagine this too: most firms are small but some firms are enormous.
The distribution of town and city sizes is heavy-tailed
Most towns and cities are small but some are very large.
Later in this lecture, we examine heavy tails in these distributions.
22.1.5. Why should we care?#
Heavy tails are common in economic data but does that mean they are important?
The answer to this question is affirmative!
When distributions are heavy-tailed, we need to think carefully about issues like
diversification and risk
forecasting
taxation (across a heavy-tailed income distribution), etc.
We return to these points below.
22.2. Visual comparisons#
In this section, we will introduce important concepts such as the Pareto distribution, Counter CDFs, and Power laws, which aid in recognizing heavy-tailed distributions.
Later we will provide a mathematical definition of the difference between light and heavy tails.
But for now let’s do some visual comparisons to help us build intuition on the difference between these two types of distributions.
22.2.1. Simulations#
The figure below shows a simulation.
The top two subfigures each show 120 independent draws from the normal distribution, which is light-tailed.
The bottom subfigure shows 120 independent draws from the Cauchy distribution, which is heavy-tailed.
n = 120
rng = np.random.default_rng(10)
fig, axes = plt.subplots(3, 1, figsize=(6, 12))
for ax in axes:
ax.set_ylim((-120, 120))
s_vals = 2, 12
for ax, s in zip(axes[:2], s_vals):
data = rng.standard_normal(n) * s
ax.plot(list(range(n)), data, linestyle='', marker='o', alpha=0.5, ms=4)
ax.vlines(list(range(n)), 0, data, lw=0.2)
ax.set_title(fr"draws from $N(0, \sigma^2)$ with $\sigma = {s}$", fontsize=11)
ax = axes[2]
distribution = cauchy()
data = distribution.rvs(n, random_state=rng)
ax.plot(list(range(n)), data, linestyle='', marker='o', alpha=0.5, ms=4)
ax.vlines(list(range(n)), 0, data, lw=0.2)
ax.set_title(f"draws from the Cauchy distribution", fontsize=11)
plt.subplots_adjust(hspace=0.25)
plt.show()
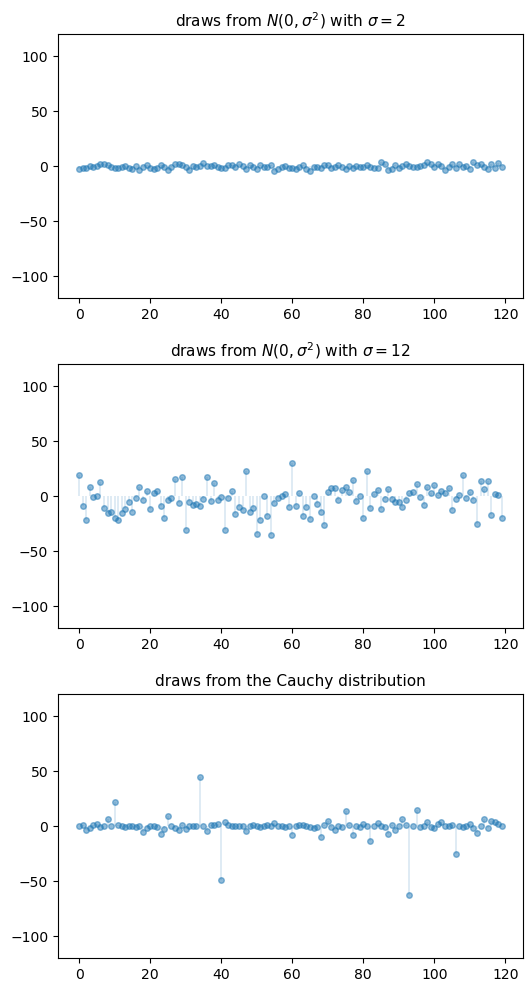
Fig. 22.6 Draws from normal and Cauchy distributions#
In the top subfigure, the standard deviation of the normal distribution is 2, and the draws are clustered around the mean.
In the middle subfigure, the standard deviation is increased to 12 and, as expected, the amount of dispersion rises.
The bottom subfigure, with the Cauchy draws, shows a different pattern: tight clustering around the mean for the great majority of observations, combined with a few sudden large deviations from the mean.
This is typical of a heavy-tailed distribution.
22.2.2. Nonnegative distributions#
Let’s compare some distributions that only take nonnegative values.
One is the exponential distribution, which we discussed in our lecture on probability and distributions.
The exponential distribution is a light-tailed distribution.
Here are some draws from the exponential distribution.
n = 120
rng = np.random.default_rng(11)
fig, ax = plt.subplots()
ax.set_ylim((0, 50))
data = rng.exponential(size=n)
ax.plot(list(range(n)), data, linestyle='', marker='o', alpha=0.5, ms=4)
ax.vlines(list(range(n)), 0, data, lw=0.2)
plt.show()
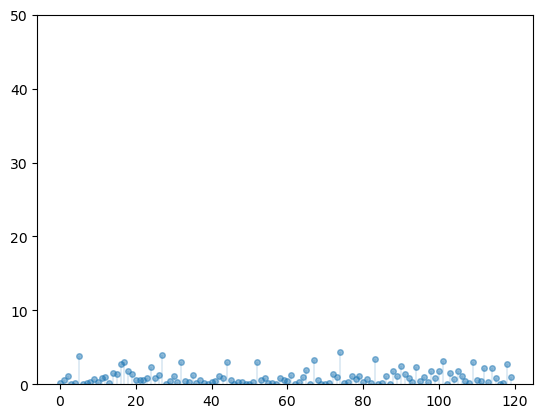
Fig. 22.7 Draws of exponential distribution#
Another nonnegative distribution is the Pareto distribution.
If \(X\) has the Pareto distribution, then there are positive constants \(\bar x\) and \(\alpha\) such that
The parameter \(\alpha\) is called the tail index and \(\bar x\) is called the minimum.
The Pareto distribution is a heavy-tailed distribution.
One way that the Pareto distribution arises is as the exponential of an exponential random variable.
In particular, if \(X\) is exponentially distributed with rate parameter \(\alpha\), then
is Pareto-distributed with minimum \(\bar x\) and tail index \(\alpha\).
Here are some draws from the Pareto distribution with tail index \(1\) and minimum \(1\).
n = 120
rng = np.random.default_rng(11)
fig, ax = plt.subplots()
ax.set_ylim((0, 80))
exponential_data = rng.exponential(size=n)
pareto_data = np.exp(exponential_data)
ax.plot(list(range(n)), pareto_data, linestyle='', marker='o', alpha=0.5, ms=4)
ax.vlines(list(range(n)), 0, pareto_data, lw=0.2)
plt.show()
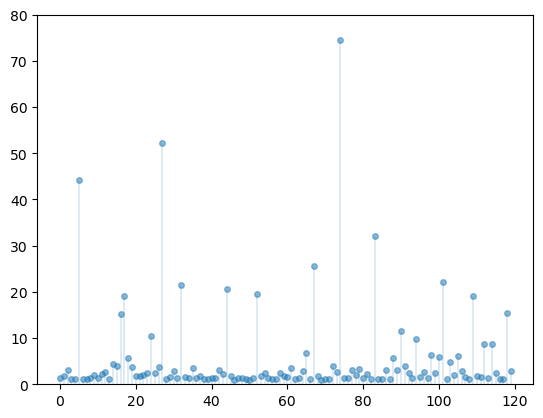
Fig. 22.8 Draws from Pareto distribution#
Notice how extreme outcomes are more common.
22.2.3. Counter CDFs#
For nonnegative random variables, one way to visualize the difference between light and heavy tails is to look at the counter CDF (CCDF).
For a random variable \(X\) with CDF \(F\), the CCDF is the function
(Some authors call \(G\) the “survival” function.)
The CCDF shows how fast the upper tail goes to zero as \(x \to \infty\).
If \(X\) is exponentially distributed with rate parameter \(\alpha\), then the CCDF is
This function goes to zero relatively quickly as \(x\) gets large.
The standard Pareto distribution, where \(\bar x = 1\), has CCDF
This function goes to zero as \(x \to \infty\), but much slower than \(G_E\).
Exercise 22.1
Show how the CCDF of the standard Pareto distribution can be derived from the CCDF of the exponential distribution.
Solution
Letting \(G_E\) and \(G_P\) be defined as above, letting \(X\) be exponentially distributed with rate parameter \(\alpha\), and letting \(Y = \exp(X)\), we have
Here’s a plot that illustrates how \(G_E\) goes to zero faster than \(G_P\).
x = np.linspace(1.5, 100, 1000)
fig, ax = plt.subplots()
alpha = 1.0
ax.plot(x, np.exp(- alpha * x), label='exponential', alpha=0.8)
ax.plot(x, x**(- alpha), label='Pareto', alpha=0.8)
ax.set_xlabel('X value')
ax.set_ylabel('CCDF')
ax.legend()
plt.show()
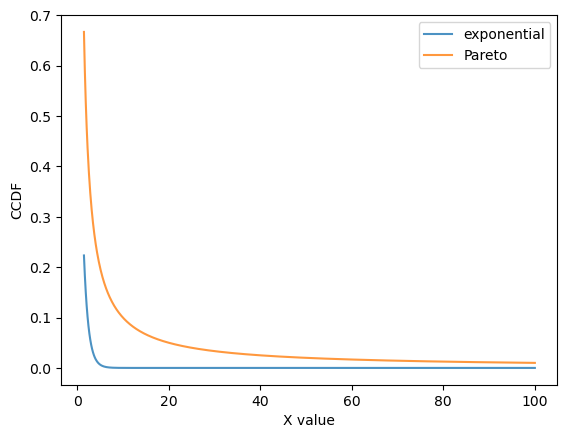
Fig. 22.9 Pareto and exponential distribution comparison#
Here’s a log-log plot of the same functions, which makes visual comparison easier.
fig, ax = plt.subplots()
alpha = 1.0
ax.loglog(x, np.exp(- alpha * x), label='exponential', alpha=0.8)
ax.loglog(x, x**(- alpha), label='Pareto', alpha=0.8)
ax.set_xlabel('log value')
ax.set_ylabel('log prob')
ax.legend()
plt.show()
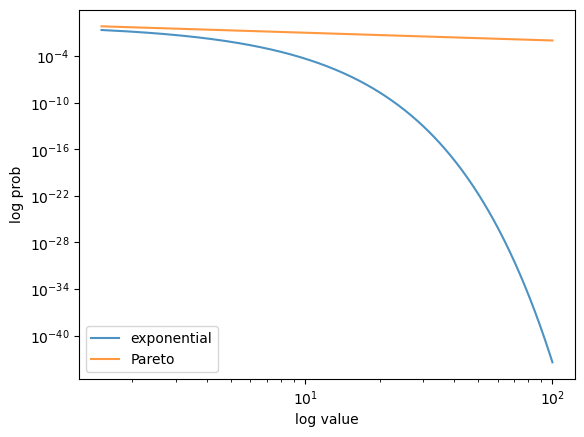
Fig. 22.10 Pareto and exponential distribution comparison (log-log)#
In the log-log plot, the Pareto CCDF is linear, while the exponential one is concave.
This idea is often used to separate light- and heavy-tailed distributions in visualisations — we return to this point below.
22.2.4. Empirical CCDFs#
The sample counterpart of the CCDF function is the empirical CCDF.
Given a sample \(x_1, \ldots, x_n\), the empirical CCDF is given by
Thus, \(\hat G(x)\) shows the fraction of the sample that exceeds \(x\).
def eccdf(x, data):
"Simple empirical CCDF function."
return np.mean(data > x)
Here’s a figure containing some empirical CCDFs from simulated data.
# Parameters and grid
x_grid = np.linspace(1, 1000, 1000)
sample_size = 1000
rng = np.random.default_rng(13)
z = rng.standard_normal(sample_size)
# Draws
data_exp = rng.exponential(size=sample_size)
data_logn = np.exp(z)
data_pareto = np.exp(rng.exponential(size=sample_size))
data_list = [data_exp, data_logn, data_pareto]
# Build figure
fig, axes = plt.subplots(3, 1, figsize=(6, 8))
axes = axes.flatten()
labels = ['exponential', 'lognormal', 'Pareto']
for data, label, ax in zip(data_list, labels, axes):
ax.loglog(x_grid, [eccdf(x, data) for x in x_grid],
'o', markersize=3.0, alpha=0.5, label=label)
ax.set_xlabel("log value")
ax.set_ylabel("log prob")
ax.legend()
fig.subplots_adjust(hspace=0.4)
plt.show()
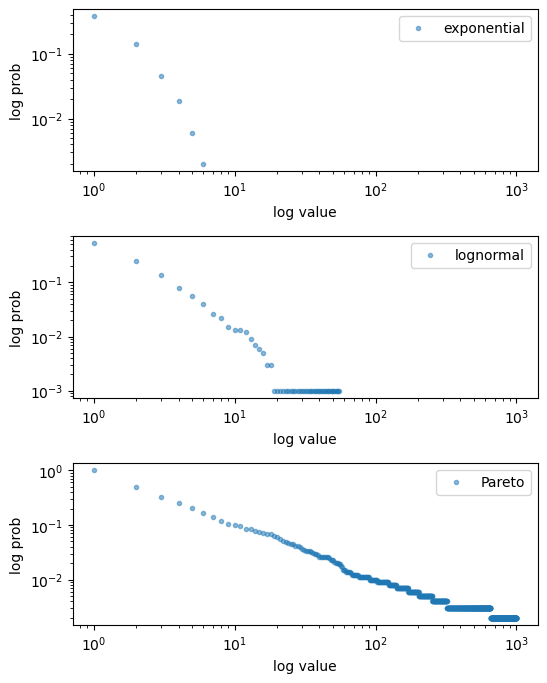
Fig. 22.11 Empirical CCDFs#
As with the CCDF, the empirical CCDF from the Pareto distributions is approximately linear in a log-log plot.
We will use this idea below when we look at real data.
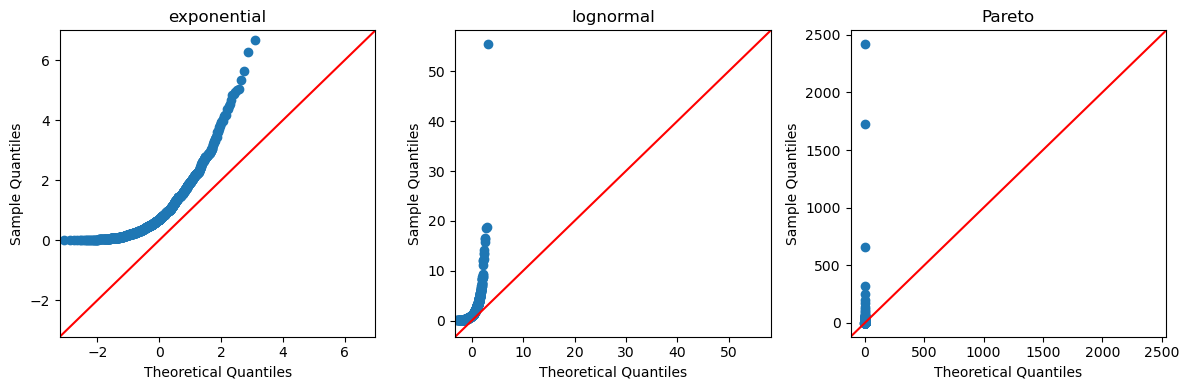
22.2.4.1. Q-Q Plots#
We can also use a qq plot to do a visual comparison between two probability distributions.
The statsmodels package provides a convenient qqplot function that, by default, compares sample data to the quintiles of the normal distribution.
If the data is drawn from a normal distribution, the plot would look like:
data_normal = rng.normal(size=sample_size)
sm.qqplot(data_normal, line='45')
plt.show()
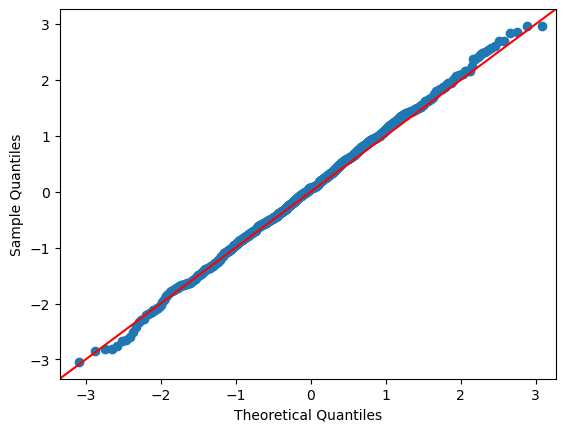
We can now compare this with the exponential, log-normal, and Pareto distributions
# Build figure
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
axes = axes.flatten()
labels = ['exponential', 'lognormal', 'Pareto']
for data, label, ax in zip(data_list, labels, axes):
sm.qqplot(data, line='45', ax=ax, )
ax.set_title(label)
plt.tight_layout()
plt.show()
22.2.5. Power laws#
One specific class of heavy-tailed distributions has been found repeatedly in economic and social phenomena: the class of so-called power laws.
A random variable \(X\) is said to have a power law if, for some \(\alpha > 0\),
We can write this more mathematically as
It is also common to say that a random variable \(X\) with this property has a Pareto tail with tail index \(\alpha\).
Notice that every Pareto distribution with tail index \(\alpha\) has a Pareto tail with tail index \(\alpha\).
We can think of power laws as a generalization of Pareto distributions.
They are distributions that resemble Pareto distributions in their upper right tail.
Another way to think of power laws is a set of distributions with a specific kind of (very) heavy tail.
22.3. Heavy tails in economic cross-sections#
As mentioned above, heavy tails are pervasive in economic data.
In fact power laws seem to be very common as well.
We now illustrate this by showing the empirical CCDF of heavy tails.
All plots are in log-log, so that a power law shows up as a linear log-log plot, at least in the upper tail.
We hide the code that generates the figures, which is somewhat complex, but readers are of course welcome to explore the code (perhaps after examining the figures).
22.3.1. Firm size#
Here is a plot of the firm size distribution for the largest 500 firms in 2020 taken from Forbes Global 2000.
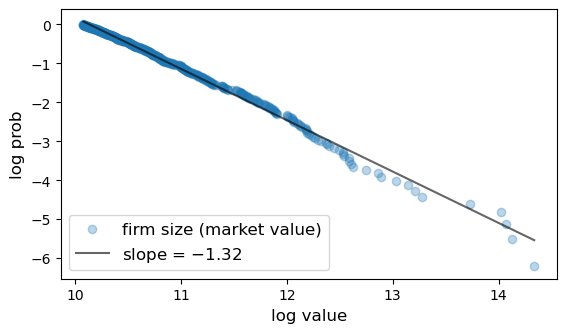
Fig. 22.12 Firm size distribution#
22.3.2. City size#
Here are plots of the city size distribution for the US and Brazil in 2023 from the World Population Review.
The size is measured by population.
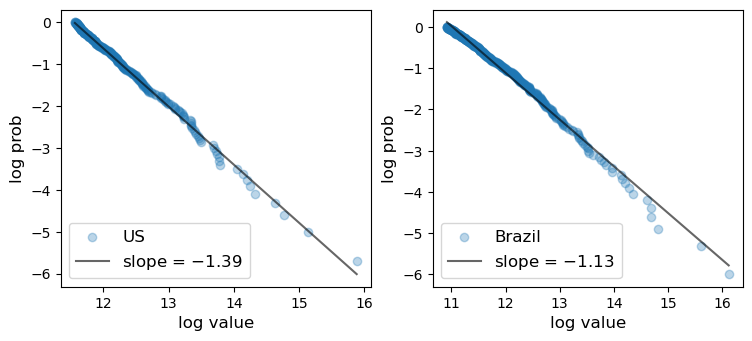
Fig. 22.13 City size distribution#
22.3.3. Wealth#
Here is a plot of the upper tail (top 500) of the wealth distribution.
The data is from the Forbes Billionaires list in 2020.
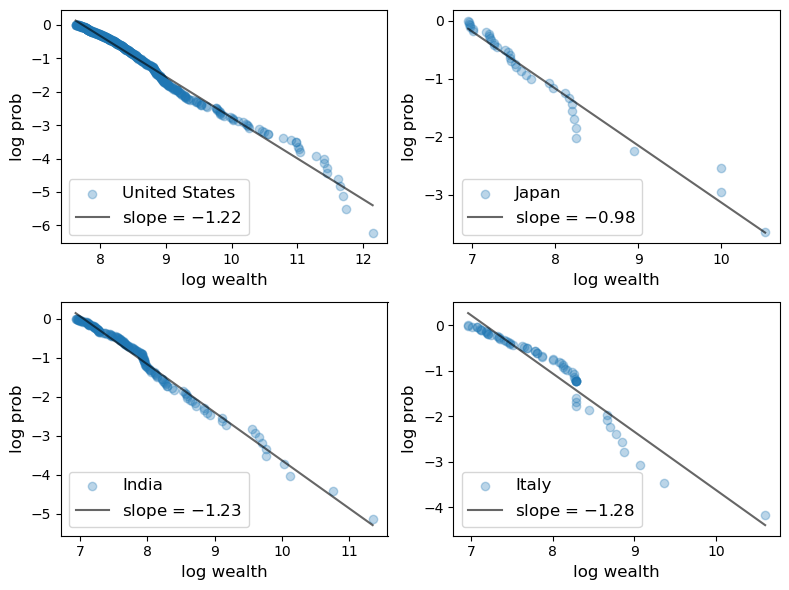
Fig. 22.14 Wealth distribution (Forbes billionaires in 2020)#
22.3.4. GDP#
Of course, not all cross-sectional distributions are heavy-tailed.
Here we show cross-country per capita GDP.
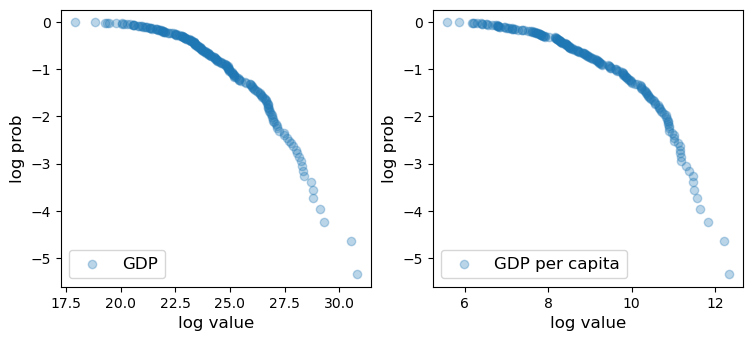
Fig. 22.15 GDP per capita distribution#
The plot is concave rather than linear, so the distribution has light tails.
One reason is that this is data on an aggregate variable, which involves some averaging in its definition.
Averaging tends to eliminate extreme outcomes.
22.4. Failure of the LLN#
One impact of heavy tails is that sample averages can be poor estimators of the underlying mean of the distribution.
To understand this point better, recall our earlier discussion of the law of large numbers, which considered IID \(X_1, \ldots, X_n\) with common distribution \(F\)
If \(\mathbb E |X_i|\) is finite, then the sample mean \(\bar X_n := \frac{1}{n} \sum_{i=1}^n X_i\) satisfies
where \(\mu := \mathbb E X_i = \int x F(dx)\) is the common mean of the sample.
The condition \(\mathbb E | X_i | = \int |x| F(dx) < \infty\) holds in most cases but can fail if the distribution \(F\) is very heavy-tailed.
For example, it fails for the Cauchy distribution.
Let’s have a look at the behavior of the sample mean in this case, and see whether or not the LLN is still valid.
from scipy.stats import cauchy
rng = np.random.default_rng(9403)
N = 1_000
distribution = cauchy()
fig, ax = plt.subplots()
data = distribution.rvs(N, random_state=rng)
# Compute sample mean at each n
sample_mean = np.empty(N)
for n in range(1, N):
sample_mean[n] = np.mean(data[:n])
# Plot
ax.plot(range(N), sample_mean, alpha=0.6, label='$\\bar{X}_n$')
ax.plot(range(N), np.zeros(N), 'k--', lw=0.5)
ax.set_xlabel(r"$n$")
ax.legend()
plt.show()
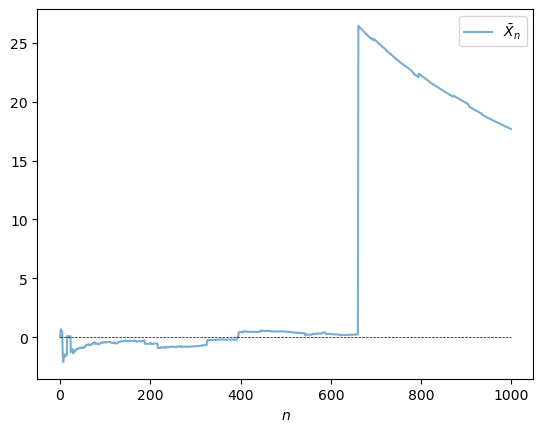
Fig. 22.16 LLN failure#
The sequence shows no sign of converging.
We return to this point in the exercises.
22.5. Why do heavy tails matter?#
We have now seen that
heavy tails are frequent in economics and
the law of large numbers fails when tails are very heavy.
But what about in the real world? Do heavy tails matter?
Let’s briefly discuss why they do.
22.5.1. Diversification#
One of the most important ideas in investing is using diversification to reduce risk.
This is a very old idea — consider, for example, the expression “don’t put all your eggs in one basket”.
To illustrate, consider an investor with one dollar of wealth and a choice over \(n\) assets with payoffs \(X_1, \ldots, X_n\).
Suppose that returns on distinct assets are independent and each return has mean \(\mu\) and variance \(\sigma^2\).
If the investor puts all wealth in one asset, say, then the expected payoff of the portfolio is \(\mu\) and the variance is \(\sigma^2\).
If instead the investor puts share \(1/n\) of her wealth in each asset, then the portfolio payoff is
Try computing the mean and variance.
You will find that
The mean is unchanged at \(\mu\), while
the variance of the portfolio has fallen to \(\sigma^2 / n\).
Diversification reduces risk, as expected.
But there is a hidden assumption here: the variance of returns is finite.
If the distribution is heavy-tailed and the variance is infinite, then this logic is incorrect.
For example, we saw above that if every \(X_i\) is Cauchy, then so is \(Y_n\).
This means that diversification doesn’t help at all!
22.5.2. Fiscal policy#
The heaviness of the tail in the wealth distribution matters for taxation and redistribution policies.
The same is true for the income distribution.
For example, the heaviness of the tail of the income distribution helps determine how much revenue a given tax policy will raise.
22.6. Classifying tail properties#
Up until now we have discussed light and heavy tails without any mathematical definitions.
Let’s now rectify this.
We will focus our attention on the right hand tails of nonnegative random variables and their distributions.
The definitions for left hand tails are very similar and we omit them to simplify the exposition.
22.6.1. Light and heavy tails#
A distribution \(F\) with density \(f\) on \(\mathbb R_+\) is called heavy-tailed if
We say that a nonnegative random variable \(X\) is heavy-tailed if its density is heavy-tailed.
This is equivalent to stating that its moment generating function \(m(t) := \mathbb E \exp(t X)\) is infinite for all \(t > 0\).
For example, the log-normal distribution is heavy-tailed because its moment generating function is infinite everywhere on \((0, \infty)\).
The Pareto distribution is also heavy-tailed.
Less formally, a heavy-tailed distribution is one that is not exponentially bounded (i.e. the tails are heavier than the exponential distribution).
A distribution \(F\) on \(\mathbb R_+\) is called light-tailed if it is not heavy-tailed.
A nonnegative random variable \(X\) is light-tailed if its distribution \(F\) is light-tailed.
For example, every random variable with bounded support is light-tailed. (Why?)
As another example, if \(X\) has the exponential distribution, with cdf \(F(x) = 1 - \exp(-\lambda x)\) for some \(\lambda > 0\), then its moment generating function is
In particular, \(m(t)\) is finite whenever \(t < \lambda\), so \(X\) is light-tailed.
One can show that if \(X\) is light-tailed, then all of its moments are finite.
Conversely, if some moment is infinite, then \(X\) is heavy-tailed.
The latter condition is not necessary, however.
For example, the lognormal distribution is heavy-tailed but every moment is finite.
22.7. Further reading#
For more on heavy tails in the wealth distribution, see e.g., [Vilfredo, 1896] and [Benhabib and Bisin, 2018].
For more on heavy tails in the firm size distribution, see e.g., [Axtell, 2001], [Gabaix, 2016].
For more on heavy tails in the city size distribution, see e.g., [Rozenfeld et al., 2011], [Gabaix, 2016].
There are other important implications of heavy tails, aside from those discussed above.
For example, heavy tails in income and wealth affect productivity growth, business cycles, and political economy.
For further reading, see, for example, [Acemoglu and Robinson, 2002], [Glaeser et al., 2003], [Bhandari et al., 2018] or [Ahn et al., 2018].
22.8. Exercises#
Exercise 22.2
Prove: If \(X\) has a Pareto tail with tail index \(\alpha\), then \(\mathbb E[X^r] = \infty\) for all \(r \geq \alpha\).
Solution
Let \(X\) have a Pareto tail with tail index \(\alpha\) and let \(F\) be its cdf.
Fix \(r \geq \alpha\).
In view of (22.2), we can take positive constants \(b\) and \(\bar x\) such that
But then
We know that \(\int_{\bar x}^\infty x^{r-\alpha-1} dx = \infty\) whenever \(r - \alpha - 1 \geq -1\).
Since \(r \geq \alpha\), we have \(\mathbb E X^r = \infty\).
Exercise 22.3
Repeat the simulation in Fig. 22.6, but replace the three distributions (two normal, one Cauchy) with three Pareto distributions using different choices of \(\alpha\).
For \(\alpha\), try 1.15, 1.5 and 1.75.
Use rng = np.random.default_rng(11) to set the seed.
Solution
from scipy.stats import pareto
rng = np.random.default_rng(11)
n = 120
alphas = [1.15, 1.50, 1.75]
fig, axes = plt.subplots(3, 1, figsize=(6, 8))
for (a, ax) in zip(alphas, axes):
ax.set_ylim((-5, 50))
data = pareto.rvs(size=n, scale=1, b=a, random_state=rng)
ax.plot(list(range(n)), data, linestyle='', marker='o', alpha=0.5, ms=4)
ax.vlines(list(range(n)), 0, data, lw=0.2)
ax.set_title(f"Pareto draws with $\\alpha = {a}$", fontsize=11)
plt.subplots_adjust(hspace=0.4)
plt.show()
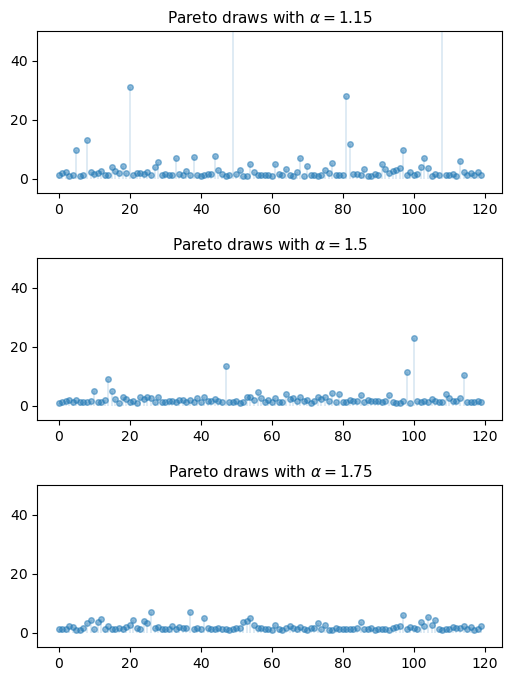
Exercise 22.4
There is an ongoing argument about whether the firm size distribution should be modeled as a Pareto distribution or a lognormal distribution (see, e.g., [Fujiwara et al., 2004], [Kondo et al., 2018] or [Schluter and Trede, 2019]).
This sounds esoteric but has real implications for a variety of economic phenomena.
To illustrate this fact in a simple way, let us consider an economy with
100,000 firms, an interest rate of r = 0.05 and a corporate tax rate of
15%.
Your task is to estimate the present discounted value of projected corporate tax revenue over the next 10 years.
Because we are forecasting, we need a model.
We will suppose that
the number of firms and the firm size distribution (measured in profits) remain fixed and
the firm size distribution is either lognormal or Pareto.
Present discounted value of tax revenue will be estimated by
generating 100,000 draws of firm profit from the firm size distribution,
multiplying by the tax rate, and
summing the results with discounting to obtain present value.
The Pareto distribution is assumed to take the form (22.1) with \(\bar x = 1\) and \(\alpha = 1.05\).
(The value of the tail index \(\alpha\) is plausible given the data [Gabaix, 2016].)
To make the lognormal option as similar as possible to the Pareto option, choose its parameters such that the mean and median of both distributions are the same.
Note that, for each distribution, your estimate of tax revenue will be random because it is based on a finite number of draws.
To take this into account, generate 100 replications (evaluations of tax revenue) for each of the two distributions and compare the two samples by
producing a violin plot visualizing the two samples side-by-side and
printing the mean and standard deviation of both samples.
For the seed use rng = np.random.default_rng(1234).
What differences do you observe?
(Note: a better approach to this problem would be to model firm dynamics and try to track individual firms given the current distribution. We will discuss firm dynamics in later lectures.)
Solution
To do the exercise, we need to choose the parameters \(\mu\) and \(\sigma\) of the lognormal distribution to match the mean and median of the Pareto distribution.
Here we understand the lognormal distribution as that of the random variable \(\exp(\mu + \sigma Z)\) when \(Z\) is standard normal.
The mean and median of the Pareto distribution (22.1) with \(\bar x = 1\) are
Using the corresponding expressions for the lognormal distribution leads us to the equations
which we solve for \(\mu\) and \(\sigma\) given \(\alpha = 1.05\).
Here is the code that generates the two samples, produces the violin plot and prints the mean and standard deviation of the two samples.
num_firms = 100_000
num_years = 10
tax_rate = 0.15
r = 0.05
β = 1 / (1 + r) # discount factor
x_bar = 1.0
α = 1.05
def pareto_rvs(n, rng):
"Uses a standard method to generate Pareto draws."
u = rng.uniform(size=n)
y = x_bar / (u**(1/α))
return y
Let’s compute the lognormal parameters:
μ = np.log(2) / α
σ_sq = 2 * (np.log(α/(α - 1)) - np.log(2)/α)
σ = np.sqrt(σ_sq)
Here’s a function to compute a single estimate of tax revenue for a particular
choice of distribution dist.
def tax_rev(dist, rng):
tax_raised = 0
for t in range(num_years):
if dist == 'pareto':
π = pareto_rvs(num_firms, rng)
else:
π = np.exp(μ + σ * rng.standard_normal(num_firms))
tax_raised += β**t * np.sum(π * tax_rate)
return tax_raised
Now let’s generate the violin plot.
num_reps = 100
rng = np.random.default_rng(1234)
tax_rev_lognorm = np.empty(num_reps)
tax_rev_pareto = np.empty(num_reps)
for i in range(num_reps):
tax_rev_pareto[i] = tax_rev('pareto', rng)
tax_rev_lognorm[i] = tax_rev('lognorm', rng)
fig, ax = plt.subplots()
data = tax_rev_pareto, tax_rev_lognorm
ax.violinplot(data)
plt.show()
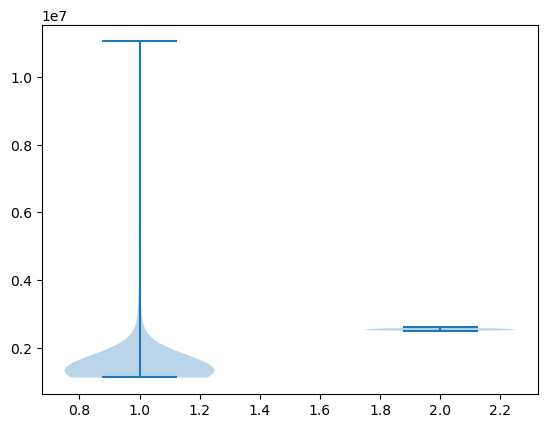
Finally, let’s print the means and standard deviations.
tax_rev_pareto.mean(), tax_rev_pareto.std()
(np.float64(1556639.6054706215), np.float64(1086577.8219896627))
tax_rev_lognorm.mean(), tax_rev_lognorm.std()
(np.float64(2555713.8231367623), np.float64(28362.016044927244))
Looking at the output of the code, our main conclusion is that the Pareto assumption leads to a lower mean and greater dispersion.
Exercise 22.5
The characteristic function of the Cauchy distribution is
Prove that the sample mean \(\bar X_n\) of \(n\) independent draws \(X_1, \ldots, X_n\) from the Cauchy distribution has the same characteristic function as \(X_1\).
(This means that the sample mean never converges.)
Solution
By independence, the characteristic function of the sample mean becomes
In view of (22.5), this is just \(e^{-|t|}\).
Thus, in the case of the Cauchy distribution, the sample mean itself has the very same Cauchy distribution, regardless of \(n\)!