3. Business Cycles#
3.1. Overview#
In this lecture we review some empirical aspects of business cycles.
Business cycles are fluctuations in economic activity over time.
These include expansions (also called booms) and contractions (also called recessions).
For our study, we will use economic indicators from the World Bank and FRED.
In addition to the packages already installed by Anaconda, this lecture requires
!pip install wbgapi
!pip install pandas-datareader
We use the following imports
import matplotlib.pyplot as plt
import pandas as pd
import datetime
import wbgapi as wb
import pandas_datareader.data as web
Here’s some minor code to help with colors in our plots.
3.2. Data acquisition#
We will use the World Bank’s data API wbgapi and pandas_datareader to retrieve data.
We can use wb.series.info with the argument q to query available data from
the World Bank.
For example, let’s retrieve the GDP growth data ID to query GDP growth data.
wb.series.info(q='GDP growth')
| id | value |
|---|---|
| NY.GDP.MKTP.KD.ZG | GDP growth (annual %) |
| 1 elements |
Now we use this series ID to obtain the data.
gdp_growth = wb.data.DataFrame('NY.GDP.MKTP.KD.ZG',
['USA', 'ARG', 'GBR', 'GRC', 'JPN'],
labels=True)
gdp_growth
| Country | YR1960 | YR1961 | YR1962 | YR1963 | YR1964 | YR1965 | YR1966 | YR1967 | YR1968 | ... | YR2016 | YR2017 | YR2018 | YR2019 | YR2020 | YR2021 | YR2022 | YR2023 | YR2024 | YR2025 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| economy | |||||||||||||||||||||
| JPN | Japan | NaN | 12.043536 | 8.908973 | 8.473642 | 11.676708 | 5.819708 | 10.638562 | 11.082142 | 12.882468 | ... | 0.753827 | 1.675332 | 0.643391 | -0.402169 | -4.168765 | 2.696574 | 0.941999 | 1.475035 | 0.104309 | NaN |
| GRC | Greece | NaN | 13.203839 | 0.364812 | 11.844867 | 9.409677 | 10.768011 | 6.494501 | 5.669486 | 7.203718 | ... | -0.031795 | 1.473125 | 2.064672 | 2.277181 | -9.196231 | 8.654498 | 5.521986 | 2.135911 | 2.086574 | NaN |
| GBR | United Kingdom | NaN | 2.701314 | 1.098696 | 4.859545 | 5.594811 | 2.130333 | 1.567450 | 2.775738 | 5.472693 | ... | 2.206520 | 3.023222 | 1.551331 | 1.256299 | -10.047897 | 8.543112 | 5.149704 | 0.271650 | 1.126423 | NaN |
| ARG | Argentina | NaN | 5.427843 | -0.852022 | -5.308197 | 10.130298 | 10.569433 | -0.659726 | 3.191997 | 4.822501 | ... | -2.080328 | 2.818503 | -2.617396 | -2.000861 | -9.900485 | 10.441812 | 6.020745 | -1.855788 | -1.342931 | NaN |
| USA | United States | NaN | 2.300000 | 6.100000 | 4.400000 | 5.800000 | 6.400000 | 6.500000 | 2.500000 | 4.800000 | ... | 1.819451 | 2.457622 | 2.966505 | 2.583825 | -2.163029 | 6.055053 | 2.512375 | 2.887556 | 2.793001 | NaN |
5 rows × 67 columns
We can look at the series’ metadata to learn more about the series (click to expand).
wb.series.metadata.get('NY.GDP.MKTP.KD.ZG')
3.3. GDP growth rate#
First we look at GDP growth.
Let’s source our data from the World Bank and clean it.
# Use the series ID retrieved before
gdp_growth = wb.data.DataFrame('NY.GDP.MKTP.KD.ZG',
['USA', 'ARG', 'GBR', 'GRC', 'JPN'],
labels=True)
gdp_growth = gdp_growth.set_index('Country')
gdp_growth.columns = gdp_growth.columns.str.replace('YR', '').astype(int)
Here’s a first look at the data
gdp_growth
| 1960 | 1961 | 1962 | 1963 | 1964 | 1965 | 1966 | 1967 | 1968 | 1969 | ... | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | 2023 | 2024 | 2025 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Country | |||||||||||||||||||||
| Japan | NaN | 12.043536 | 8.908973 | 8.473642 | 11.676708 | 5.819708 | 10.638562 | 11.082142 | 12.882468 | 12.477895 | ... | 0.753827 | 1.675332 | 0.643391 | -0.402169 | -4.168765 | 2.696574 | 0.941999 | 1.475035 | 0.104309 | NaN |
| Greece | NaN | 13.203839 | 0.364812 | 11.844867 | 9.409677 | 10.768011 | 6.494501 | 5.669486 | 7.203718 | 11.563668 | ... | -0.031795 | 1.473125 | 2.064672 | 2.277181 | -9.196231 | 8.654498 | 5.521986 | 2.135911 | 2.086574 | NaN |
| United Kingdom | NaN | 2.701314 | 1.098696 | 4.859545 | 5.594811 | 2.130333 | 1.567450 | 2.775738 | 5.472693 | 1.939138 | ... | 2.206520 | 3.023222 | 1.551331 | 1.256299 | -10.047897 | 8.543112 | 5.149704 | 0.271650 | 1.126423 | NaN |
| Argentina | NaN | 5.427843 | -0.852022 | -5.308197 | 10.130298 | 10.569433 | -0.659726 | 3.191997 | 4.822501 | 9.679526 | ... | -2.080328 | 2.818503 | -2.617396 | -2.000861 | -9.900485 | 10.441812 | 6.020745 | -1.855788 | -1.342931 | NaN |
| United States | NaN | 2.300000 | 6.100000 | 4.400000 | 5.800000 | 6.400000 | 6.500000 | 2.500000 | 4.800000 | 3.100000 | ... | 1.819451 | 2.457622 | 2.966505 | 2.583825 | -2.163029 | 6.055053 | 2.512375 | 2.887556 | 2.793001 | NaN |
5 rows × 66 columns
We write a function to generate plots for individual countries taking into account the recessions.
Let’s start with the United States.
fig, ax = plt.subplots()
country = 'United States'
ylabel = 'GDP growth rate (%)'
plot_series(gdp_growth, country,
ylabel, 0.1, ax,
g_params, b_params, t_params)
plt.show()
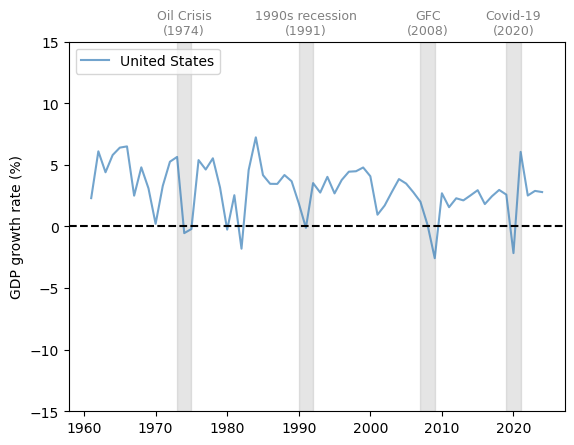
Fig. 3.1 United States (GDP growth rate %)#
GDP growth is positive on average and trending slightly downward over time.
We also see fluctuations in GDP growth over time, some of which are quite large.
Let’s look at a few more countries to get a basis for comparison.
The United Kingdom (UK) has a similar pattern to the US, with a slow decline in the growth rate and significant fluctuations.
Notice the very large dip during the Covid-19 pandemic.
fig, ax = plt.subplots()
country = 'United Kingdom'
plot_series(gdp_growth, country,
ylabel, 0.1, ax,
g_params, b_params, t_params)
plt.show()
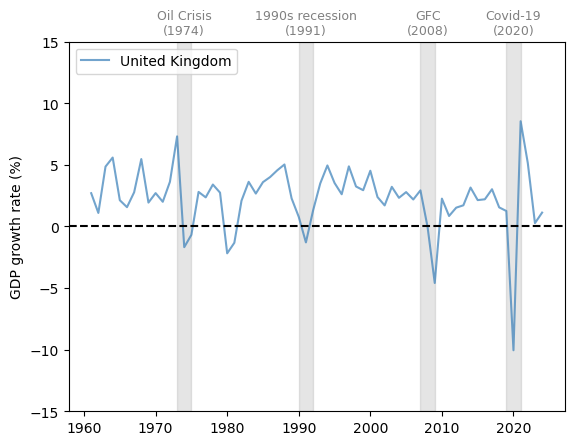
Fig. 3.2 United Kingdom (GDP growth rate %)#
Now let’s consider Japan, which experienced rapid growth in the 1960s and 1970s, followed by slowed expansion in the past two decades.
Major dips in the growth rate coincided with the Oil Crisis of the 1970s, the Global Financial Crisis (GFC) and the Covid-19 pandemic.
fig, ax = plt.subplots()
country = 'Japan'
plot_series(gdp_growth, country,
ylabel, 0.1, ax,
g_params, b_params, t_params)
plt.show()
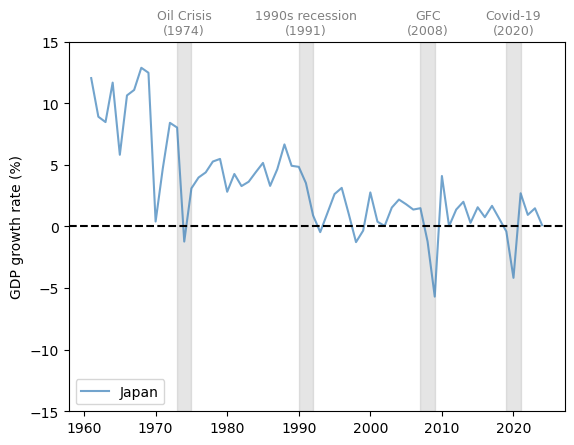
Fig. 3.3 Japan (GDP growth rate %)#
Now let’s study Greece.
fig, ax = plt.subplots()
country = 'Greece'
plot_series(gdp_growth, country,
ylabel, 0.1, ax,
g_params, b_params, t_params)
plt.show()
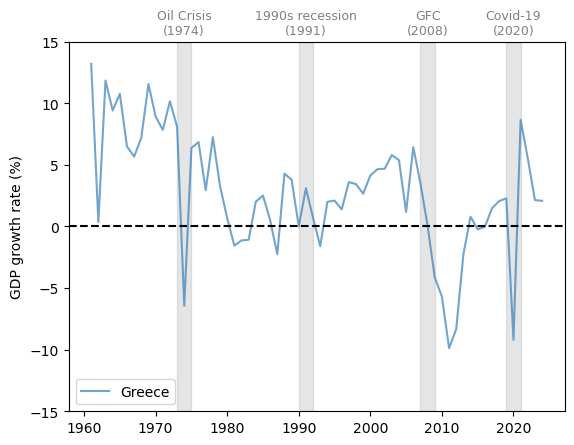
Fig. 3.4 Greece (GDP growth rate %)#
Greece experienced a very large drop in GDP growth around 2010-2011, during the peak of the Greek debt crisis.
Next let’s consider Argentina.
fig, ax = plt.subplots()
country = 'Argentina'
plot_series(gdp_growth, country,
ylabel, 0.1, ax,
g_params, b_params, t_params)
plt.show()
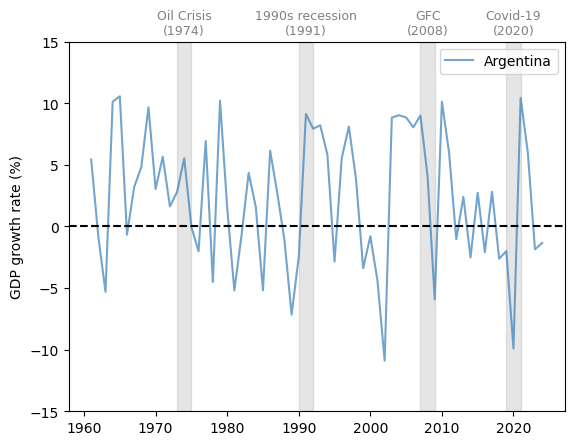
Fig. 3.5 Argentina (GDP growth rate %)#
Notice that Argentina has experienced far more volatile cycles than the economies examined above.
At the same time, Argentina’s growth rate did not fall during the two developed economy recessions in the 1970s and 1990s.
3.4. Unemployment#
Another important measure of business cycles is the unemployment rate.
We study unemployment using rate data from FRED spanning from 1929-1942 to 1948-2022, combined unemployment rate data over 1942-1948 estimated by the Census Bureau.
Let’s plot the unemployment rate in the US from 1929 to 2022 with recessions defined by the NBER.
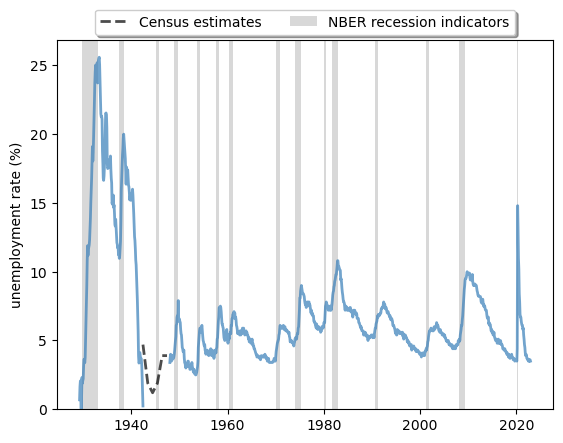
Fig. 3.6 Long-run unemployment rate, US (%)#
The plot shows that
expansions and contractions of the labor market have been highly correlated with recessions.
cycles are, in general, asymmetric: sharp rises in unemployment are followed by slow recoveries.
It also shows us how unique labor market conditions were in the US during the post-pandemic recovery.
The labor market recovered at an unprecedented rate after the shock in 2020-2021.
3.5. Synchronization#
In our previous discussion, we found that developed economies have had relatively synchronized periods of recession.
At the same time, this synchronization did not appear in Argentina until the 2000s.
Let’s examine this trend further.
With slight modifications, we can use our previous function to draw a plot that includes multiple countries.
Here we compare the GDP growth rate of developed economies and developing economies.
We use the United Kingdom, United States, Germany, and Japan as examples of developed economies.
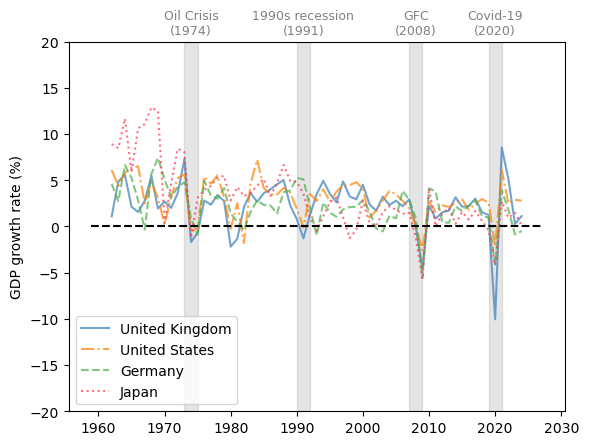
Fig. 3.7 Developed economies (GDP growth rate %)#
We choose Brazil, China, Argentina, and Mexico as representative developing economies.
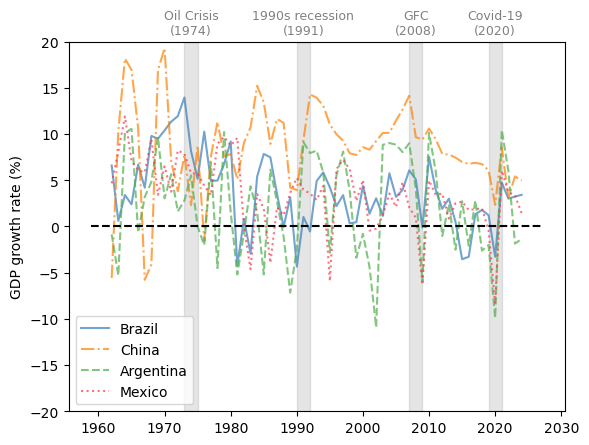
Fig. 3.8 Developing economies (GDP growth rate %)#
The comparison of GDP growth rates above suggests that business cycles are becoming more synchronized in 21st-century recessions.
However, emerging and less developed economies often experience more volatile changes throughout the economic cycles.
Despite the synchronization in GDP growth, the experience of individual countries during the recession often differs.
We use the unemployment rate and the recovery of labor market conditions as another example.
Here we compare the unemployment rate of the United States, the United Kingdom, Japan, and France.
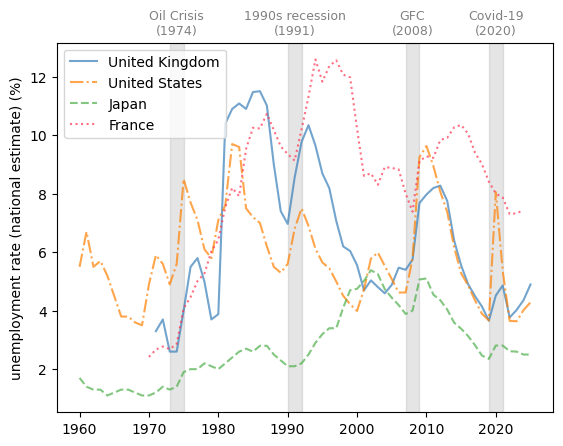
Fig. 3.9 Developed economies (unemployment rate %)#
We see that France, with its strong labor unions, typically experiences slower labor market recoveries after negative shocks because union influence often leads to stringent employment protection laws, high firing costs, and rigid wage structures. While these measures protect existing workers, they reduce firms’ flexibility to adjust labor costs and hiring in response to changing economic conditions, causing lower labour market adaptability during recoveries.
We also notice that Japan has a history of very low and stable unemployment rates.
3.6. Leading indicators and correlated factors#
Examining leading indicators and correlated factors helps policymakers to understand the causes and results of business cycles.
We will discuss potential leading indicators and correlated factors from three perspectives: consumption, production, and credit level.
3.6.1. Consumption#
Consumption depends on consumers’ confidence in their income and the overall performance of the economy in the future.
One widely cited indicator for consumer confidence is the consumer sentiment index published by the University of Michigan.
Here we plot the University of Michigan Consumer Sentiment Index and year-on-year core consumer price index (CPI) change from 1978-2022 in the US.
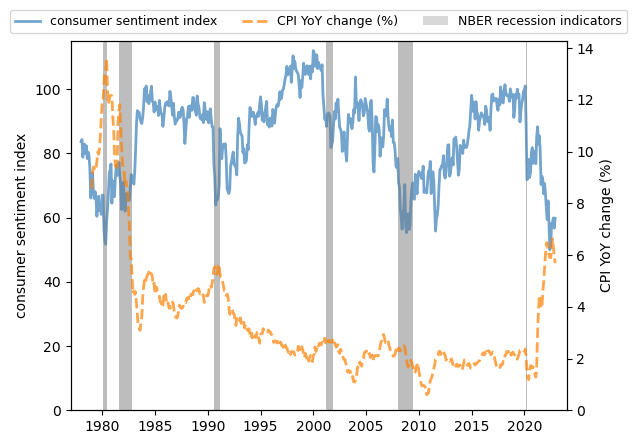
Fig. 3.10 Consumer sentiment index and YoY CPI change, US#
We see that
consumer sentiment often remains high during expansions and drops before recessions.
there is a clear negative correlation between consumer sentiment and the CPI.
When the price of consumer commodities rises, consumer confidence diminishes.
This trend is more significant during stagflation.
3.6.2. Production#
Real industrial output is highly correlated with recessions in the economy.
However, it is not a leading indicator, as the peak of contraction in production is delayed relative to consumer confidence and inflation.
We plot the real industrial output change from the previous year from 1919 to 2022 in the US to show this trend.
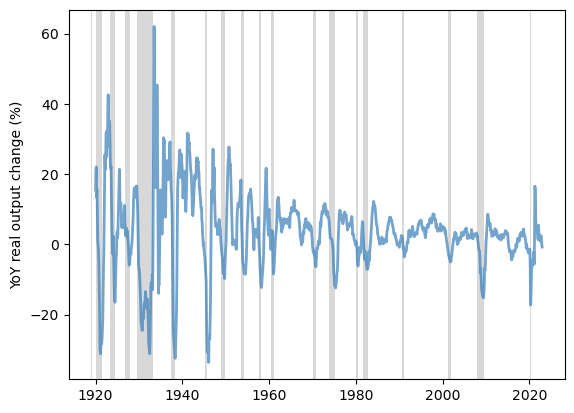
Fig. 3.11 YoY real output change, US (%)#
We observe the delayed contraction in the plot across recessions.
3.6.3. Credit level#
Credit contractions often occur during recessions, as lenders become more cautious and borrowers become more hesitant to take on additional debt.
This is due to factors such as a decrease in overall economic activity and gloomy expectations for the future.
One example is domestic credit to the private sector by banks in the UK.
The following graph shows the domestic credit to the private sector as a percentage of GDP by banks from 1970 to 2022 in the UK.
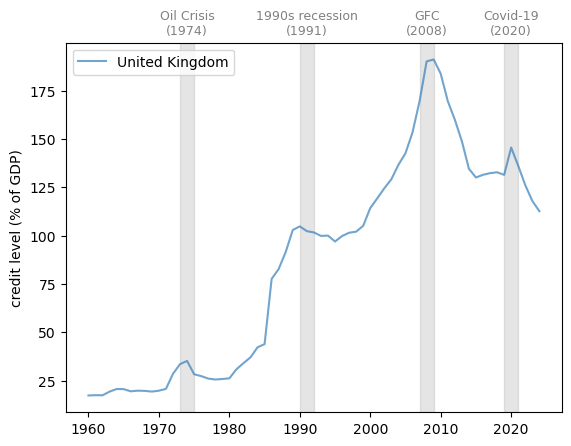
Fig. 3.12 Domestic credit to private sector by banks (% of GDP)#
Note that the credit rises during economic expansions and stagnates or even contracts after recessions.